Seit über einem Jahr gibt es nun die Möglichkeit, Cubes, die man – wie bisher auch – in Visual Studio erstellt, nun direkt nach Power BI in einen Arbeitsbereich zu deployen.
Dies hat einige Vorteile:
- Man muss keine eigenen Analysis Services Dienste mehr vorhalten (weder on prem noch Azure Analysis Services)
- Das spart ggf. Lizenzen, Server-Kapazitäten und verringert die Komplexität einer Lösung
- Man kann dennoch auf die Datasets von außerhalb zugreifen (z.B. Excel Pivot, Reporting Services – generell mit jedem Tool, das Zugriffe auf Cubes unterstützt)
Als wir zum ersten Mal ein solches Cube-Deployment allerdings durchgeführt haben, ging das nicht, ohne über die ein oder andere Klippe zu stolpern. Deshalb beschreibe ich hier, wie man vorgehen muss.
Voraussetzungen
Ausgangssituation: Ich gehe davon aus, dass wir im Visual Studio einen Cube erstellt haben.
Wichtig ist, dass wir den Kompatibilitätsmodus auf 1500 gesetzt haben:
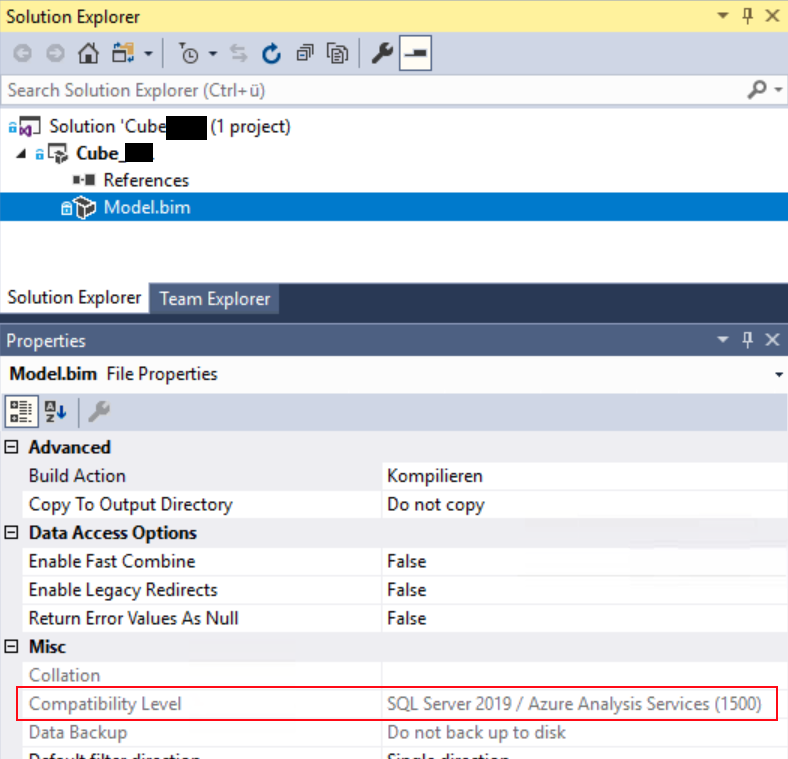
(Man beachte, dass diese Einstellung nur bearbeitet werden kann, wenn das Model.bim im Visual Studio geöffnet ist)
Build und Deployment
Über einen Build erzeugen wie dann ein asdatabase-File:
Das erzeugt im bin-Folder folgende Dateien (das ist noch alles unabhängig von unserem Deployment nach Power BI Premium):
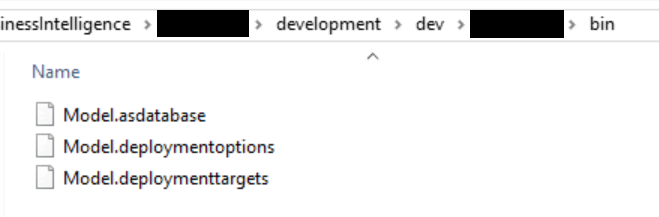
In der Regel machen wir es nun so, dass wir in unser Quell-Code-Verwaltungssystem das „Model.asdatabase“ einchecken und von einem Branch in den nächsten (-> Test -> Prod) bewegen – die anderen Dateien werden für den Deployment Wizard nicht benötigt. Hier werden wir gleich einen Fallstrick sehen – aber dazu gleich mehr.
Nun wollen wir das so erzeugte Model.asdatabase-File in einen Power BI Premium-Arbeitsbereich deployen. Dazu benötigen wir als erstes die Adresse, auf die wir es deployen können. Diese finden wir im Arbeitsbereich.
Es ist zu beachten, dass das ein Premium-Feature ist. Der Arbeitsbereich muss deshalb entweder einer Power-BI-Premium-Kapazität zugeordnet sein (erkennbar am Symbol ![]() ) oder unter einer Power BI Premium Einzelbenutzerlizenz laufen (erkennbar am Symbol
) oder unter einer Power BI Premium Einzelbenutzerlizenz laufen (erkennbar am Symbol ![]() ). Unter Einstellungen findet man dann im Reiter Premium die Adresse für die Verbindung:
). Unter Einstellungen findet man dann im Reiter Premium die Adresse für die Verbindung:
Mit der Arbeitsbereichverbindung kann man sich dann auch im SQL Server Management Studio auf den XMLA-Endpoint verbinden. Das werden wir später noch brauchen.
Nun können wir versuchen, den Cube zu deployen. Dazu starten wir den Analysis Services Deployment Wizard und wählen die Model.asdatabase-Datei aus. Als Server tragen wir die powerbi://-Adresse von oben ein:
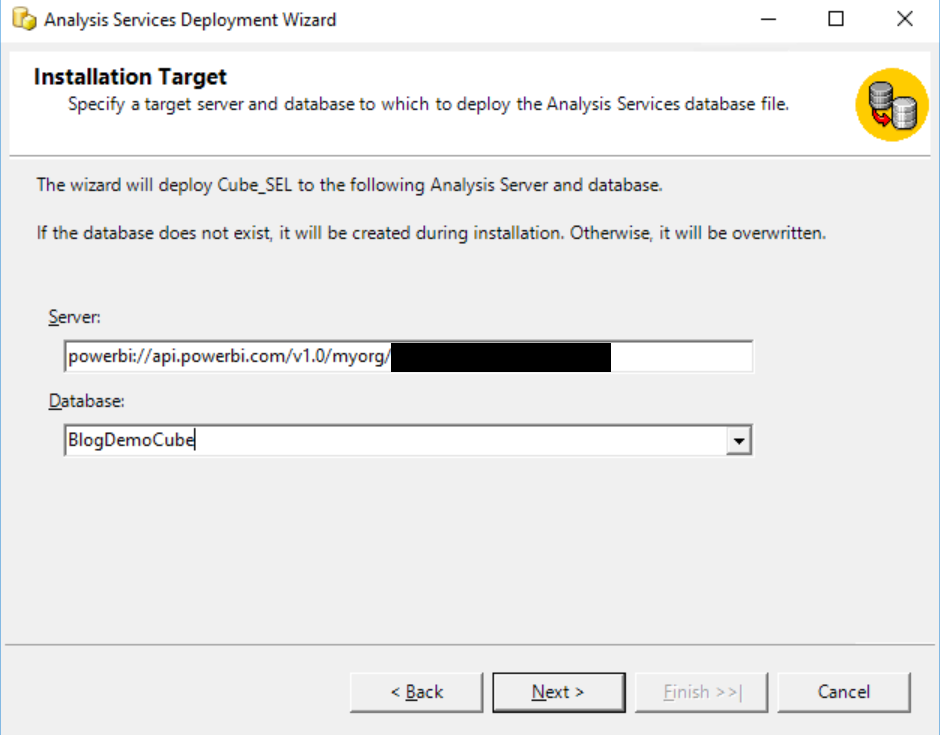
Die Eintragungen auf den nächsten Seiten sind nicht relevant, zumal wir ja den Cube zum ersten Mal deployen. In der Regel deploye ich sonst Rollen nicht und übernehme die bisher geltenden Einstellungen. Auf das Default Procesisng verzichten wir jetzt (wir machen das nachher vom SQL Server Management Studio aus).
Witzigerweise erhalten wir die Fehlermeldung „Die Datenbank „BlogDemoCube“ ist nicht vorhanden, oder Sie besitzen keine Zugriffsberechtigung.“ Das ist richtig – aber wir wollen den Cube ja auch erstmalig deployen. Hier der Screen Shot:
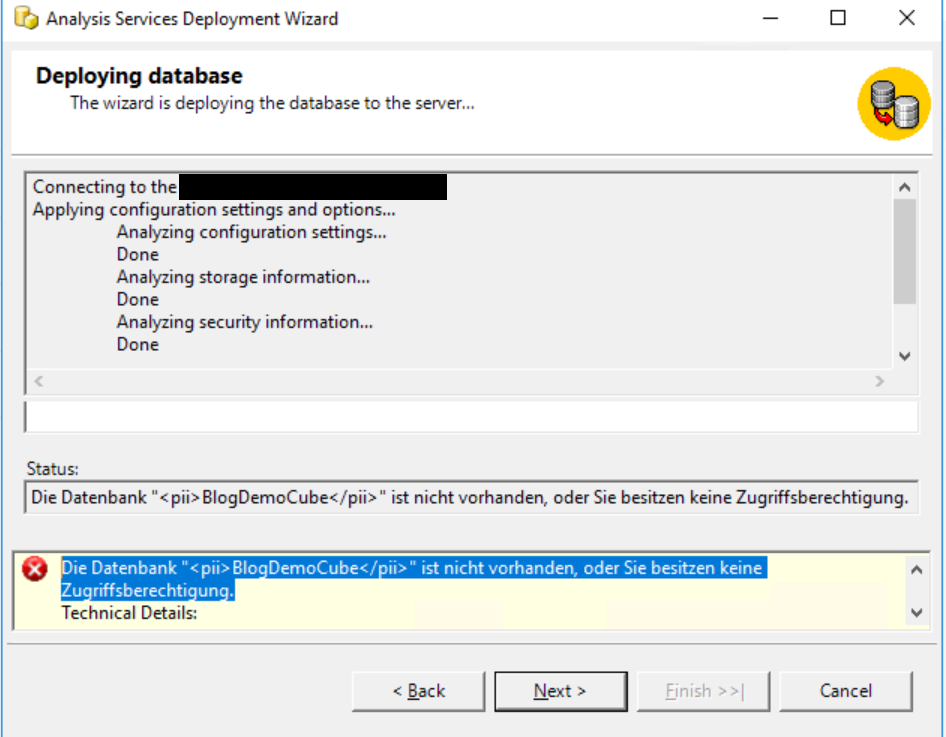
Die Lösung für dieses Problem ist, die Datei „Model.deploymentoptions“, die wir vorher gesehen haben, auch in das Verzeichnis zu legen, von wo aus wir die Datei „Model.asdatabase“ deployen.
Wenn wir das aus dem bin-Verzeichnis direkt machen, wäre uns das ganze also gar nicht passiert, da Visual Studio diese Datei dort ja ablegt. Wie gesagt, verwenden wir aber unterschiedliche Branches für unsere Umgebungen und haben dort nur das Model.asdatabase eingecheckt und bisher (onprem Analysis Services oder Azure Analysis Services) konnten wir auch nur mit dem Model.asdatabase deployen.
Die Datei „Model.deploymentoptions“ enthält darüber hinaus auch keine Informationen, die nicht im Wizard abgefragt werden. Das macht das ganze umso komischer.
Die „Model.deploymentoptions“-Datei sieht so aus (es ist also tatsächlich keine wertvolle Information, sondern kann einfach so übernommen werden):
<DeploymentOptions xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2"
xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200"
xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200">
<TransactionalDeployment>false</TransactionalDeployment>
<PartitionDeployment>DeployPartitions</PartitionDeployment>
<RoleDeployment>DeployRolesRetainMembers</RoleDeployment>
<ProcessingOption>Default</ProcessingOption>
<ADALCache>None</ADALCache>
<OutputScript></OutputScript>
<ImpactAnalysisFile></ImpactAnalysisFile>
<ConfigurationSettingsDeployment>Deploy</ConfigurationSettingsDeployment>
<OptimizationSettingsDeployment>Deploy</OptimizationSettingsDeployment>
<WriteBackTableCreation>UseExisting</WriteBackTableCreation>
</DeploymentOptions>
Durchläuft man nun nochmal den Deployment-Prozess, ändert sich die Fehlermeldung zu „Der Vorgang wird nur für ein Modell unterstützt, dessen Eigenschaft „DefaultPowerBIDataSourceVersion“ in Power BI Premium auf „PowerBI_V3″ festgelegt ist.“:
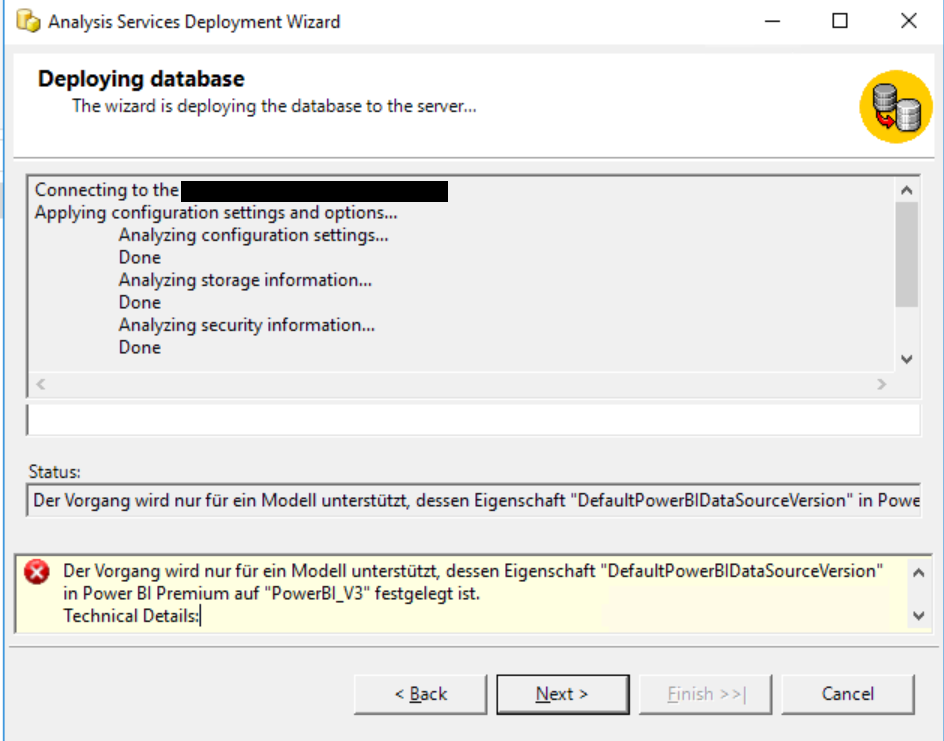
Diese Fehlermeldung ist immerhin aussagekräftig. Wir lösen das Problem, indem wir die datei Model.asdatabase in einem Editor (sagen wir Notepad++) bearbeiten. Wir fügen nach „culture“ die geforderte Eigenschaft ein: „defaultPowerBIDataSourceVersion“: „powerBI_V3“,
Vor der Bearbeitung sieht es so aus:
{
"name": "xxxxxxx",
"compatibilityLevel": 1500,
"model": {
"culture": "de-DE",
"discourageImplicitMeasures": true,
"dataSources": [
Und nach der Bearbeitung so:
{
"name": "xxxxxxx",
"compatibilityLevel": 1500,
"model": {
"culture": "de-DE",
"defaultPowerBIDataSourceVersion": "powerBI_V3",
"discourageImplicitMeasures": true,
"dataSources": [
Nun funktioniert das Deployment 🙂
Der Cube ist im Arbeitsbereich sichtbar:
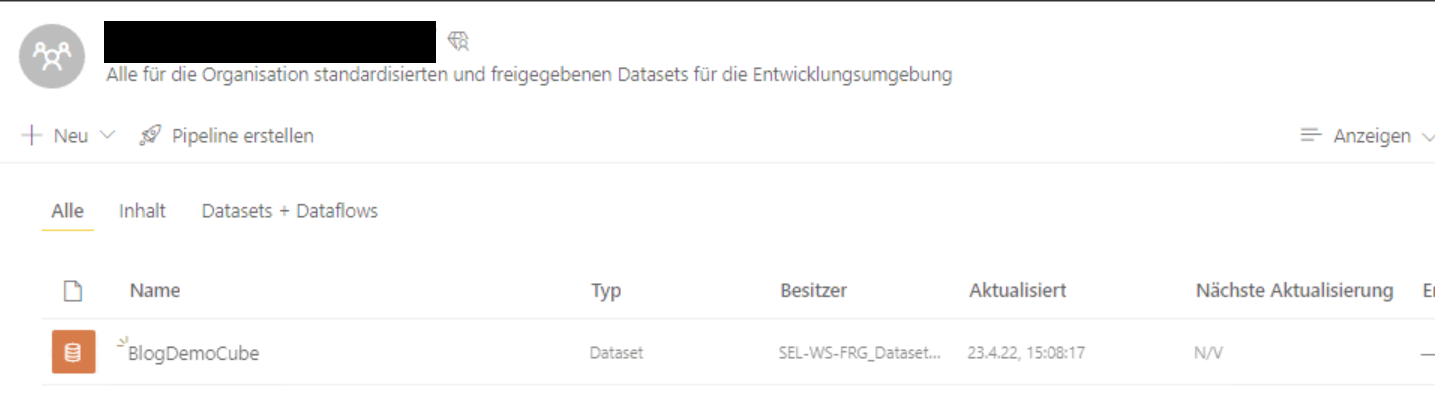
Außerdem sieht man ihn im SQL Server Management Studio:

Allerdings sind wir noch nicht fertig, da wir den Cube noch verarbeiten müssen.
Davor möchte ich aber noch ein paar Hinweise geben:
- Beide „Hacks“ (Model.deploymentoptions und defaultPowerBIDataSourceVersion) sind nur für das erste Deployment relevant. Deployt man eine neue Version des Cubes über ein bestehendes Power BI Premium Dataset, sind beide Veränderungen nicht mehr notwendig.
- Man könnte defaultPowerBIDataSourceVersion auch im Model.bim eintragen. Allerdings ist das nicht ratsam, da dann das Model.bim nicht mehr in einem Arbeitsbereichserver geöffnet werden kann und man somit nicht mehr im Visual Studio daran weiterarbeiten kann.
Cube verarbeiten
Machen wir also weiter: Wie nach jedem Deployment (auch nach Azure Analysis Services) muss man die Credentials neu eintragen, die für die Verbindung auf die zugrundeliegende Datenbank benutzt werden:
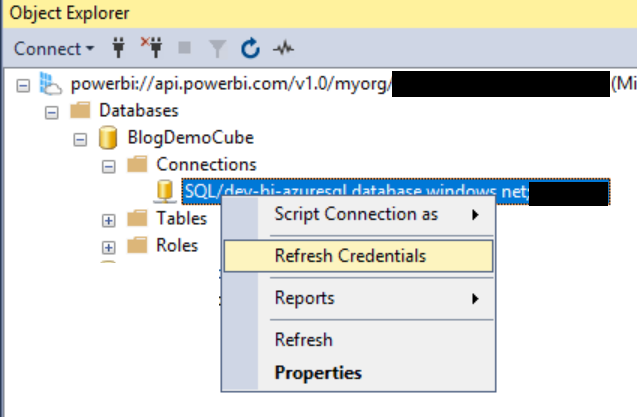
(In unserem Fall verwenden wir SQL Server Authentifizierung auf einen SQL Server in Azure)
Nun könnten wir – wenn es ein Azure Analysis Services-Cube wäre, die Cubeverarbeitung erfolgreich durchführen. Wenn wir aber nun die Verarbeitung starten, kommt eine Fehlermeldung:
Die Fehlermeldung lautet: „Failed to save modifications to the server. Error returned: ‚{„error“:{„code“:“DMTS_DatasourceHasNoCredentialError„,“pbi.error“:{„code“:“DMTS_DatasourceHasNoCredentialError“,“details“:[{„code“:“Server“,“detail“:{„type“:1,“value“:“//servername//“}},{„code“:“Database“,“detail“:{„type“:1,“value“:“//datenbankname//“}},{„code“:“ConnectionType“,“detail“:{„type“:0,“value“:“Sql“}}],“exceptionCulprit“:1}}}“. Das ist überraschend, da wir ja die Credentials gesetzt haben. Wir müssen aber noch in der Power BI App im Arbeitsbereich Einstellungen des Datsets machen:
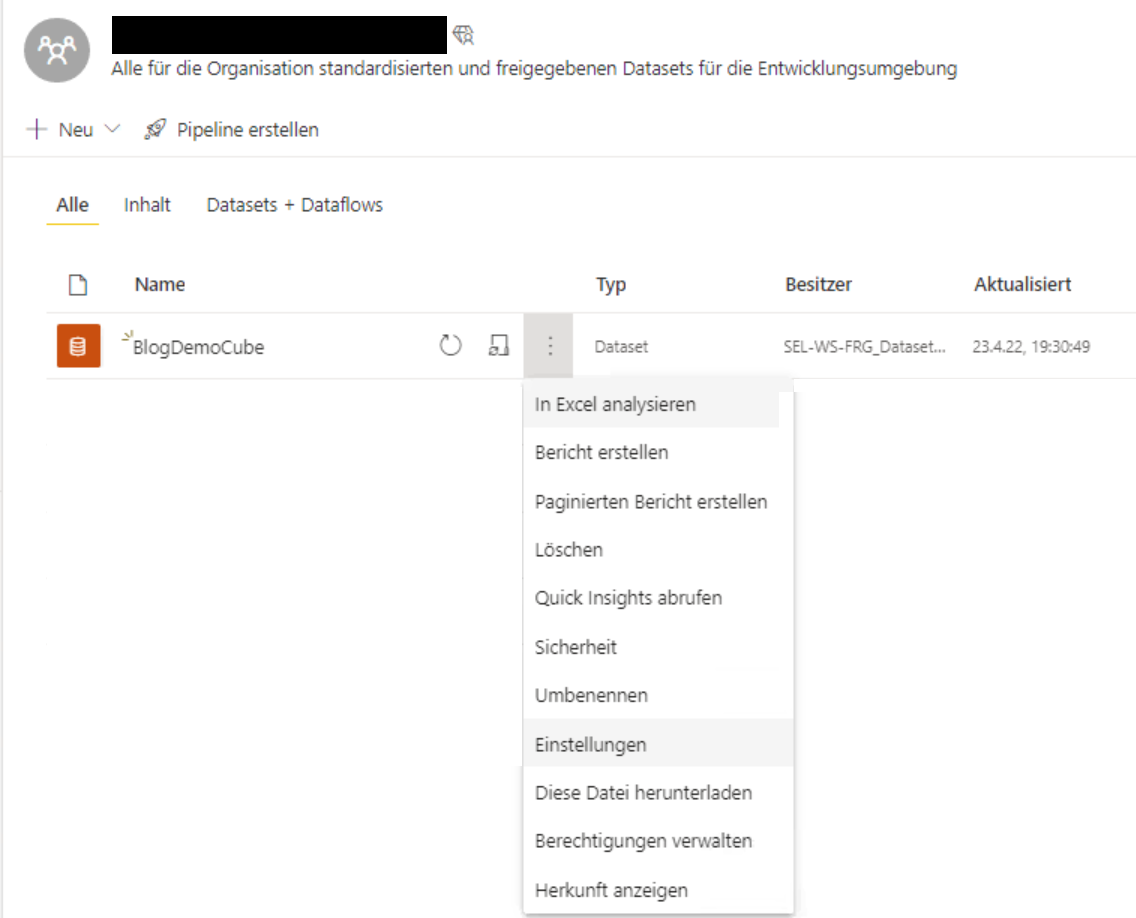
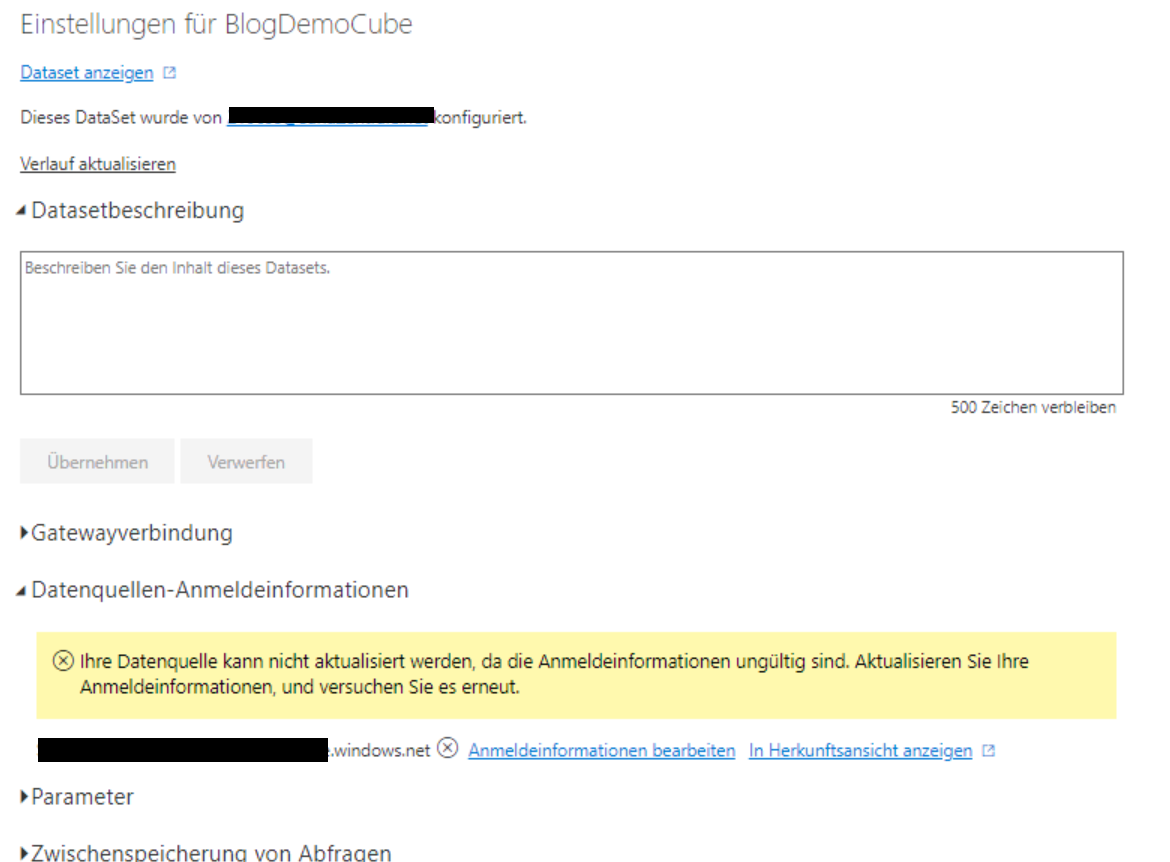
Hier sehen wir schon unter „Datenquellen-Anmeldeinformationen“ den Fehler: „Ihre Datenquelle kann nicht aktualisiert werden, da die Anmeldeinformationen ungültig sind. Aktualisieren Sie Ihre Anmeldeinformationen, und versuchen Sie es erneut.“
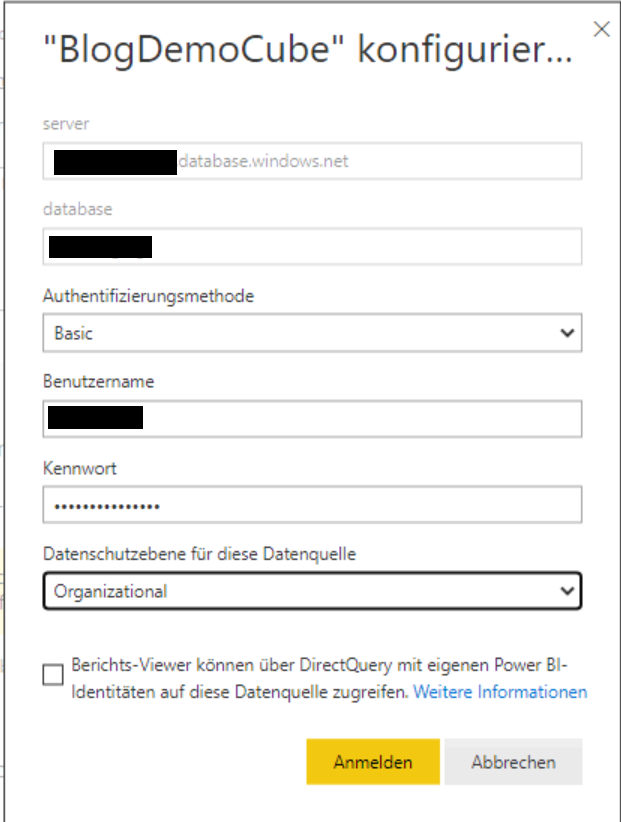
Die Lösung ist nun nahe liegend: Unter „Anmeldeinformationen bearbeiten“ muss man die gleichen Credentials nochmal eintragen:
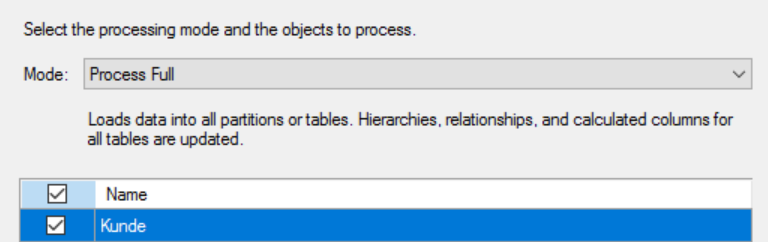
Mit diesen Einstellungen funktioniert jetzt die Cubeverarbeitung:
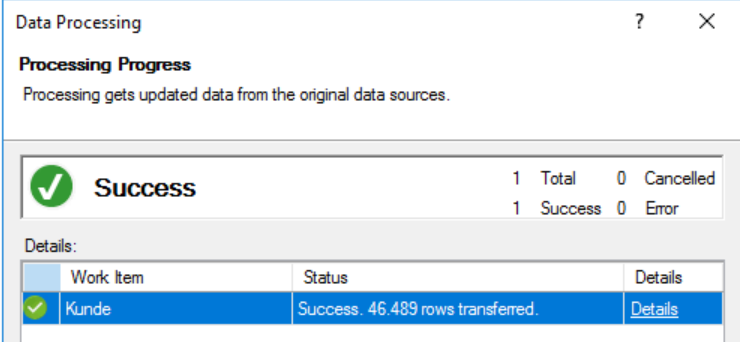
Damit haben wir die Aufgabe komplett erledigt.
Eine Anmerkung gibt es allerdings noch: Ich habe den Fall mit einer Datenquelle in Azure durchgespielt. Wenn die Datenquelle on premise liegt, ändert sich die letzte Aktion (Einstellungen des Datasets) leicht: In diesem Fall müssen dort die Gatewayeinstellungen korrekt gesetzt werden:
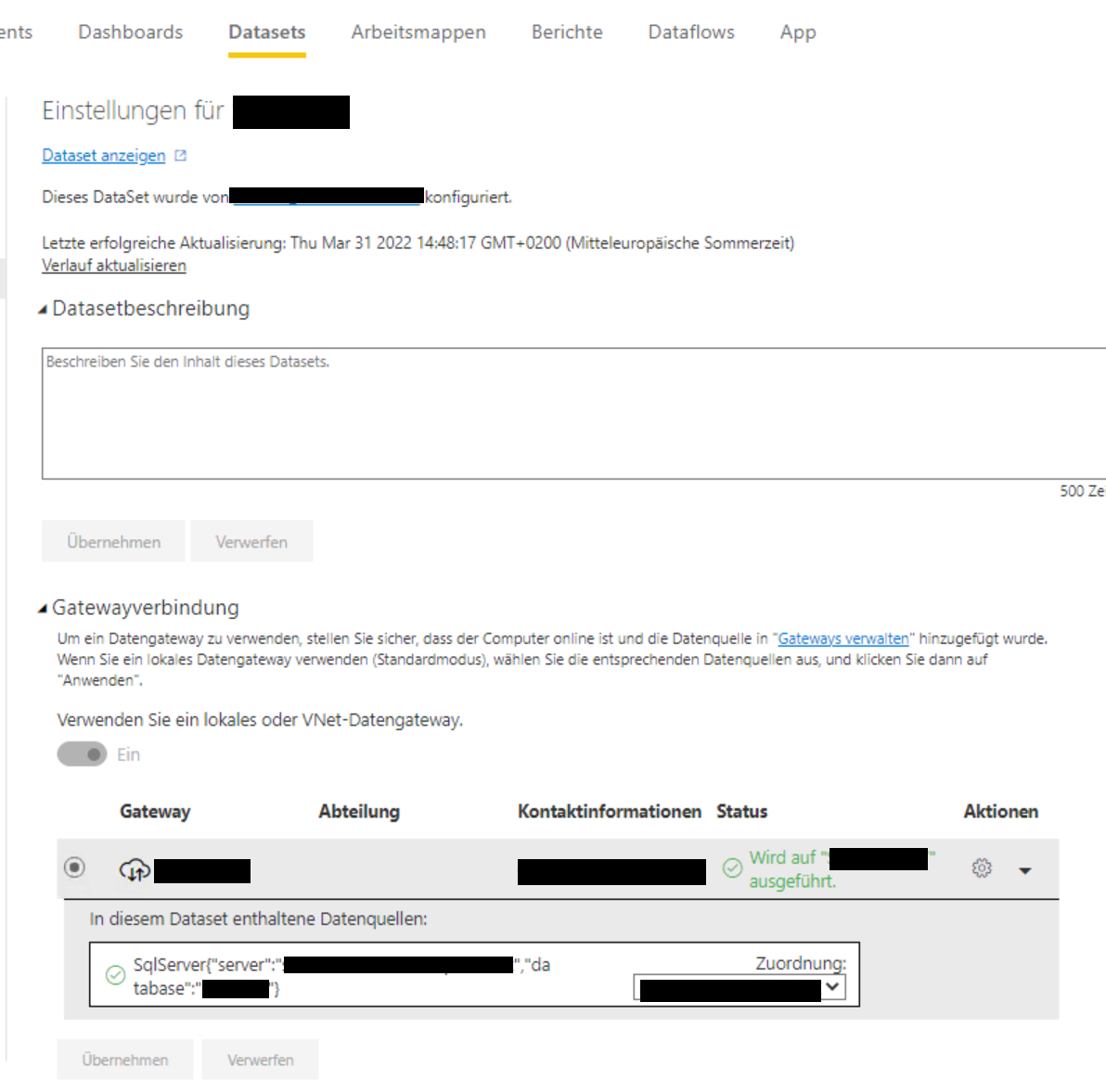
Damit man diese Einstellung machen kann, muss der eigene User als Mitglied auf dem gateway eingetragen sein (über Power BI > Einstellungen > Gateways verwalten).