In SSIS-Paketen können alle möglichen Einstellungen in Konfigurationsdateien ausgelagert werden. Insbesondere können damit
- die Eigenschaften von Verbindungen wie ConnectionString, User, Passwort
- oder Variablen wie Name des zu durchsuchenden Datei-Ordners oder ähnliches
extern konfiguriert werden – ganz analog zur web.config in ASP.NET oder app.config in Windows-Programmen. Theoretisch ist es möglich, viel mehr Attribute als oben genannte in der Konfigurationsdatei zu pflegen – aus Übersichtlichkeitsgründen ist das aber nicht empfohlen.
Dies hat den Sinn, dass das Paket in der Entwicklungs-, Test- und Produktionsumgebung immer gleich ist und nur die Konfigurationsdateien bei einer Installation angepasst werden. Dadurch wird sichergestellt, dass wirklich das getestete Paket in Produktion geht und nicht aus Versehen beim Öffnen im Visual Studio irgendwelche Einstellungen angepasst wurden. Dies ist in meinen Augen – neben vielen anderen Features – ein wesentlicher Vorteil von SSIS gegenüber seinem Vorgänger DTS.
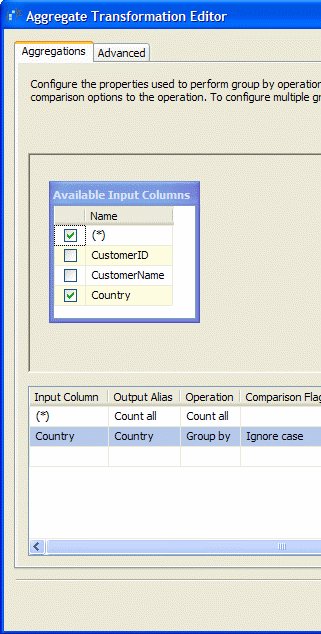
Konfigurationsdateien werden erstellt über SSIS > Package Configurations… :
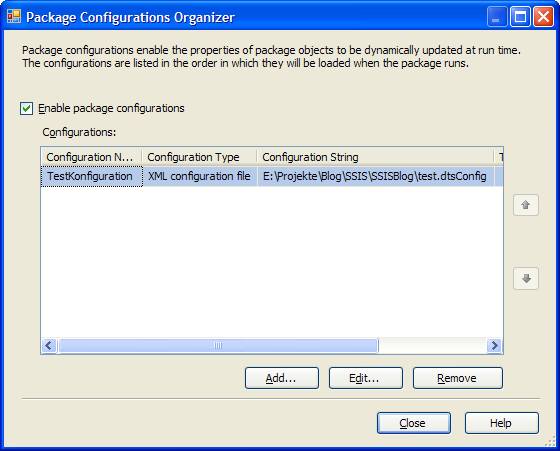
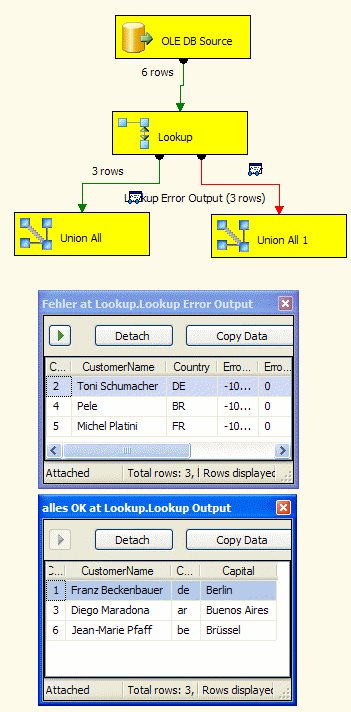
In der Regel werden XML-Konfigurationsdateien verwendet. Dort kann man den Ort der Konfigurationsdatei und die enthaltenen Attribute angeben. Dadurch erzeugt das Visual Studio die entsprechende Konfigurationsdatei. In dieser Konfigurationsdatei sind alle Werte der Attribute gespeichert, so wie sie derzeit (im Verbindungsmanager, Variablenfenster, etc.) definiert sind. Einzige Ausnahme: Falls im Verbindungsmanager ein Passwort verwendet wird, wird in der Konfigurationsdatei zwar dieses Attribut angelegt, aber nicht der Wert übernommen. (erste kleine Falle)
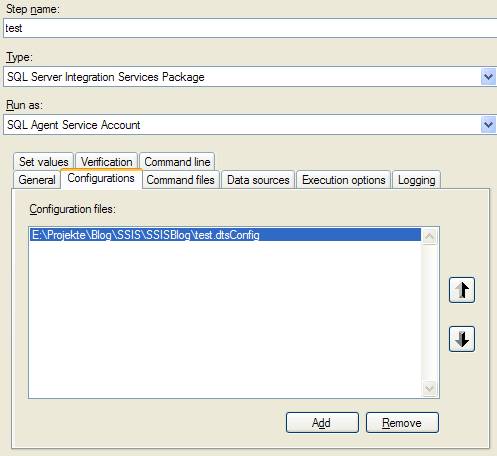
Nun ist die Idee, bei der Installation in der Produktiv-Umgebung das dtsx-Paket unverändert zu lassen und nur die Konfigurationsdatei anzupassen. Beim Starten des Pakets kann man dann die zu verwendende Konfigurationsdatei angeben (z.B. im SQL Server Agent oder beim direkten Aufruf von DTExec) und diese wird beim Ausführen des Pakets verwendet.
Allerdings gibt es ein paar Fallen, die man umschiffen sollte:
Falle 1: Änderungen an Variablen während der Entwicklung gehen beim Starten des Pakets im Visual Studio verloren:
Wenn man im Visual Studio Eigenschaften ändert, die bereits in die Konfigurationsdatei exportiert wurden, ist diese Änderung wirkungslos. Beim Start des Pakets wird ja die Konfigurationsdatei geladen und dessen Wert verwendet. Eine automatische Aktualisierung der Konfigurationsdatei bei Änderungen im Visual Studio findet (glücklicherweise) nicht statt.
Falle 2: Das Paket versucht beim Start die im Paket definierte Konfigurationsdatei zu laden
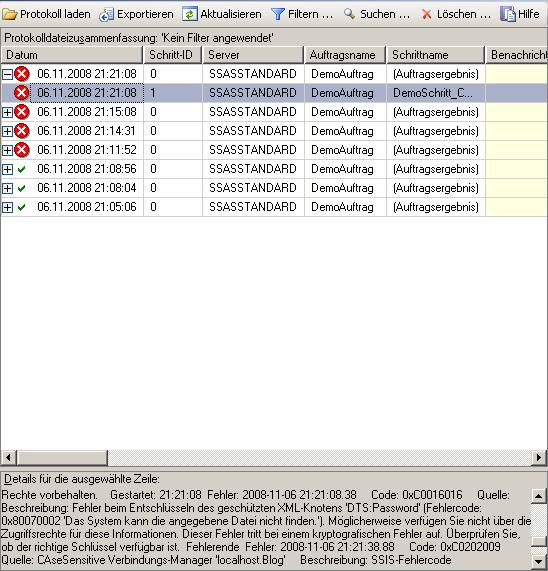
Im produktiven Umfeld liegt die Konfigurationsdatei wahrscheinlich nicht am selben Ort (im Dateisystem) wie in der Entwicklungsumgebung. Wenn man nun das Paket (wie unter Idee beschrieben) in der Produktion unter Angabe der Produktions-Konfigurationsdatei startet, so versucht das Paket zunächst die Datei zu laden, deren Pfad im Paket (s. obiger Screenshot) definiert ist. Diese Datei wird in der Regel nicht gefunden werden. Dies wird als Fehler protokolliert – das Paket bricht aber nicht ab. Danach wird die beim Aufruf mitgegebene Konfigurationsdatei geladen. Somit läuft das Paket sauber durch – allerdings ist ein Fehler protokolliert, der Verwirrung stiften kann. Deswegen ist es am sinnvollsten, den Haken bei „Enable package configurations“ (s. Screenshot) wieder zu entfernen. Durch diesen Haken hat man sich somit nur auf einfache Art und Weise eine Konfigurationsdatei erstellen lassen (anstelle sie komplett selbst manuell zu erstellen).
Nun könnte man sich wundern, ob dann trotzdem die beim Aufruf mitgegebene Konfigurationsdatei geladen wird. Die Bedeutung des Hakens ist in meinen Augen nämlich etwas verwirrend. Es besagt nämlich nicht „Dieses Paket hat eine Kofnigurationsdatei mit den dort eingestellten Attributen“. Egal ob der Haken gesetzt ist oder nicht, kann eine Konfigurationsdatei beim Start angegeben werden, die beliebige Attribute verändert, also auch Attribute, die nicht im Visual Studio zum Export in die Konfigurationsdatei markiert worden waren. Der Haken besagt somit, dass „Dieses Paket lädt beim Start automatisch die angegebene Konfigurationsdatei – danach werden die beim Start übergebenen Konfigurationsdateien geladen“.
Dieses Verhalten ist in meinen Augen wenig intuitiv – aber so ist es halt. Dadurch kann man sein eigenes Paket also auch nicht schützen, so dass bestimmte Attribute nicht von außen durch Konfigurationsdateien überschrieben werden können.
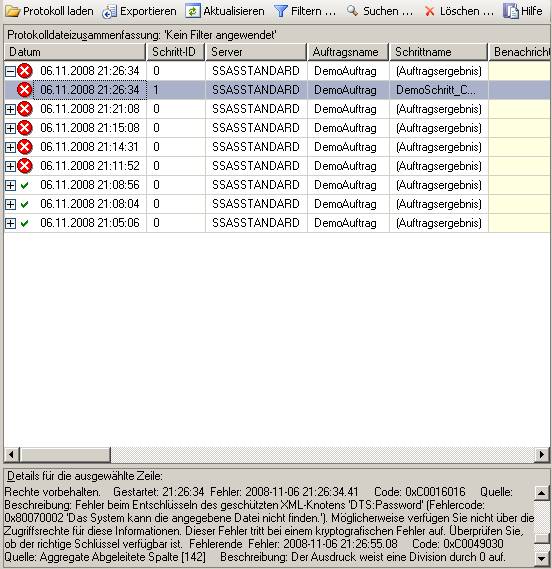
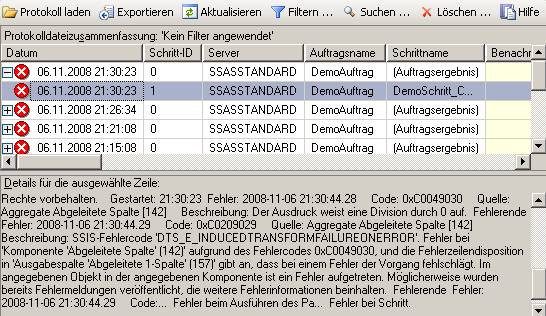
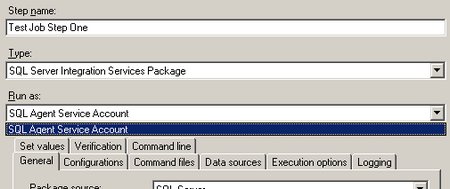
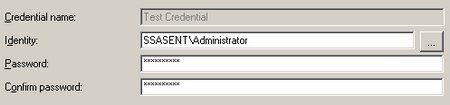
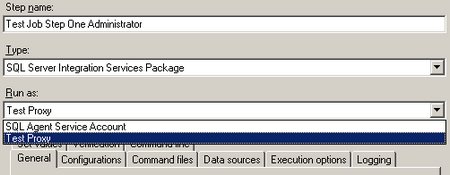
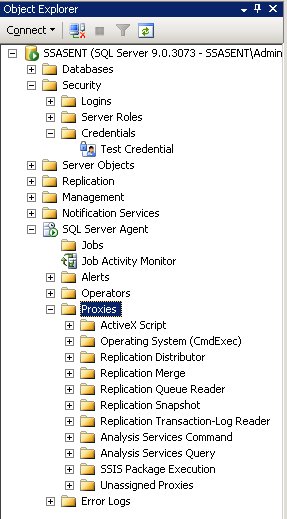 – muss dieser Credential nun für die Ausführung von SSIS-Paketen definiert werden. Dazu erstellt man einen neuen Proxy unter einem beliebigen Namen, der das neu eingegebene Credential verwendet. Bei den erlaubten Subsystemen setzt man den Haken bei den SSIS-Paketen (und allen weiteren gewünschten Systemen):
– muss dieser Credential nun für die Ausführung von SSIS-Paketen definiert werden. Dazu erstellt man einen neuen Proxy unter einem beliebigen Namen, der das neu eingegebene Credential verwendet. Bei den erlaubten Subsystemen setzt man den Haken bei den SSIS-Paketen (und allen weiteren gewünschten Systemen):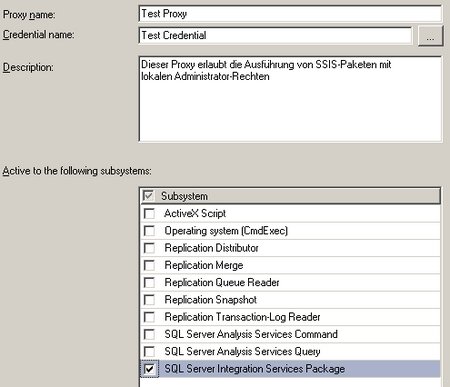
{kind=link}