Reporting Services hat ein Kalendersteuerelement, in dem man Datumswerte einfach eingeben kann, wenn ein Prompt vom Typ Date / Time ist. Heute möchte ich beschreiben, wie man das verwenden kann, wenn man einen Bericht erstellt, der auf einem Analysis Services-Cube basiert. Beim Cube ist (in der Regel) das Problem, dass es zwar eine Zeit-Dimension gibt, diese aber natürlich wie alle Dimensionen einen Member Unique Name (also Key) wie z.B. „[Intervall].[Datum].&[20081012]“ oder „[Intervall].[Datum].&[3207]“ haben. Dies ist offensichtlich ein String und kein DateTime, weswegen beim Standard-Vorgehen der Reporting Services eine Kombobox mit allen Datumswerten erstellt.
Aber hier im Detail das Vorgehen:
Im Wizard zum Erstellen der Abfrage gehen wir wie folgt vor:
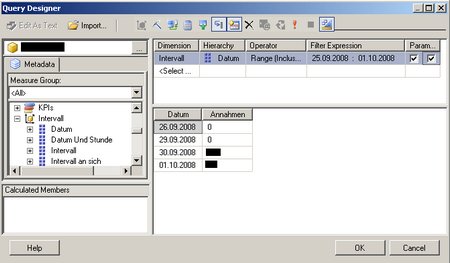
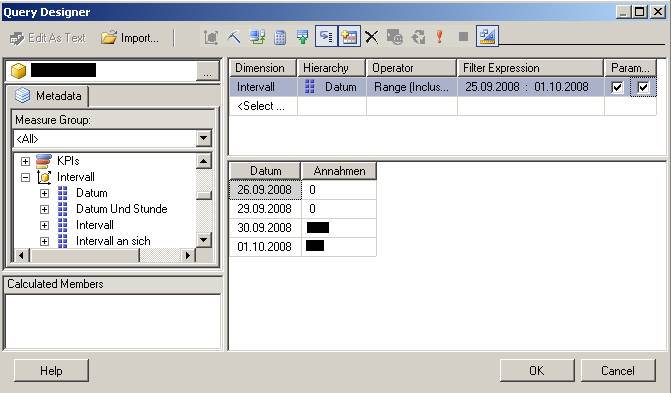
(Zum Vergrößern auf das Bild klicken)
Ich habe einfach eine Kennzahl und das Datum in die Abfrage gezogen und einen Filter auf das Datum gesetzt, wobei ich (wichtig!) die beiden Checkboxen bei den Parametern gesetzt habe.
Bei der Berichtsausführung werden die beiden Parameter über Komboboxen realisiert:
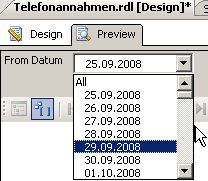
Dazu hat nämlich der Wizard zwei versteckte Data Sets angelegt, die die entsprechenden Werte liefern:
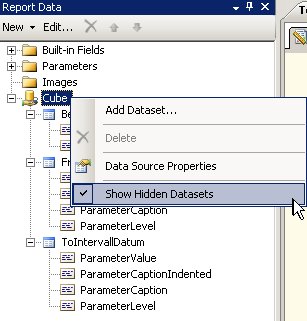
Als nächstes müssen wir das MDX anpassen. (Im Query Designer auf  klicken)
klicken)
Der Wizard hat folgendes MDX erstellt:
SELECT NON EMPTY { [Measures].[Annahmen] } ON COLUMNS, NON EMPTY { ([Intervall].[Datum].[Datum].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM ( SELECT ( STRTOMEMBER(@FromIntervallDatum, CONSTRAINED) : STRTOMEMBER(@ToIntervallDatum, CONSTRAINED) ) ON COLUMNS FROM [<CubeName>]) CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
Die beiden mit @-benannten Ausdrücke sind die Prompts.
Wir müssen nun den Teil „STRTOMEMBER(@FromIntervallDatum, CONSTRAINED) “ so abändern, dass dort eine Variable vom Typ DateTime eine Rolle spielt. Der Schlüssel eines Datumselements in diesem Fall sieht so aus „[Intervall].[Datum].&[3190]“, wobei die ID die Anzahl der Tage zwischen dem 1.1.2000 und dem betreffenden Tag ist.
Gehen wir nun davon aus, dass wir einen Prompt @von vom Typ DateTime haben, müsste der STRTOMEMBER so aussehen:
STRTOMEMBER(„[Intervall].[Datum].&[“ +cstr( datediff(„d“, DateSerial(2000, 1, 1), @von )) + „]“)
Die DateSerial-Funktion verwende ich hier aus hygienischen Gründen, um keinen Cast von String auf DateTime (der abhängig von der Locale wäre) zu verwenden)
Auf das CONSTRAINED verwende ich, da sonst der Query Designer meckert.
Wenn man selbst natürlich einen anderen Key benutzt, muss dies angepasst werden. Bei einem Key im Format YYYYMMDD, also [Intervall].[Datum].&[20091205], müsste die Formel so sein:
STRTOMEMBER(„[Intervall].[Datum].&[“ +cstr( year(@von) ) + right(„0“ + cstr(month(@von), 2) + right(„0“ + cstr(day(@von), 2) + „]“)
Nun müssen wir noch den Parameter der Abfrage definieren (über  ):
):
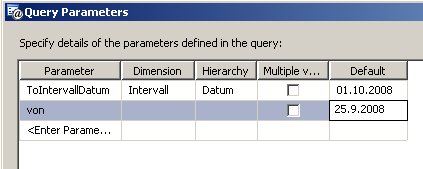
Damit existiert noch nicht der Prompt.
Unter den Eigenschaften des Datasets erscheint der Parameter @von bereits:
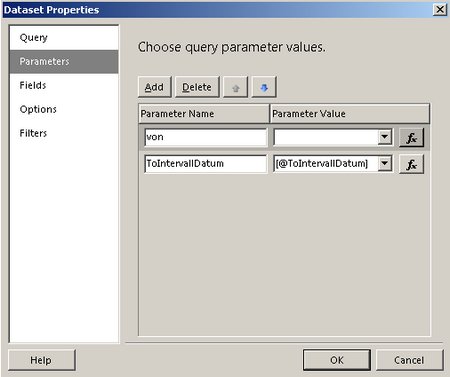
Dort tragen wir in „Parameter Value“ einfach „[@von]“ ein.
Damit wird automatisch ein Report Parameter von angelegt
 , den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
, den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
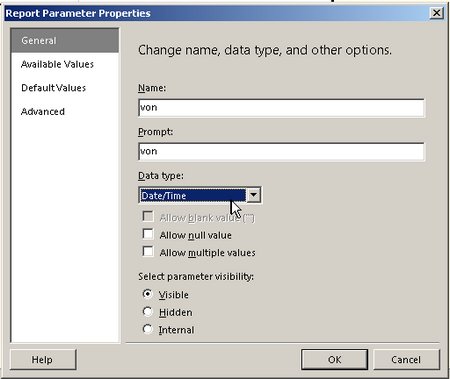
(Außerdem löschen wir den nicht mehr benötigten Prompt „FromIntervallDatum“)
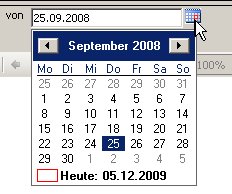
Damit steht jetzt auch hier das Kalendersteuerelement zur Verfügung: