Zu dem Standard-Aufgaben bei SSAS-Projekten gehören KPIs, wobei Ist- und Planwerte verglichen und danach der Status einer KPI berechnet wird. Heute möchte ich mich auf den Status fokusieren.
Eine normale Regel könnte sein:
- Wenn Ist >= Plan, dann Status grün
- Wenn Ist >= 90% des Plans, dann Status gelb
- Sonst Rot
Das sähe im MDX-Skript in etwa so aus:
CREATE MEMBER CURRENTCUBE.[Measures].[OPE_Status]
AS iif( [Measures].[OPE] >= [Measures].[OPE_Plan] , 1,
iif( [Measures].[OPE] >= [Measures].[OPE_Plan] * 0.9, 0, -1)),
VISIBLE = 1;
oder
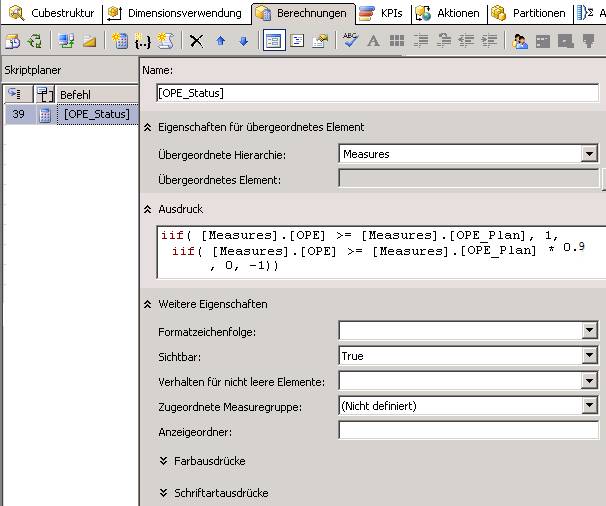
Dabei steht verabredungsgemäß +1 für grün, 0 für gelb, -1 für rot (wenn es natürlich auch andere Möglichkeiten gibt).
Möglicherweise will man nun aber den Faktor 90% für die Schwelle zwischen Gelb und Rot (oder auch den Schwellwert 100% für die Grenze zwischen Grün und Gelb) dynamisch gestalten – zum Beispiel durch die Eingabe in einer Administrationskonsole. Dann wäre es schön, wenn man dieses MDX dynamisch anpassen könnte.
Deswegen beschreibe ich hier, wie das geht:
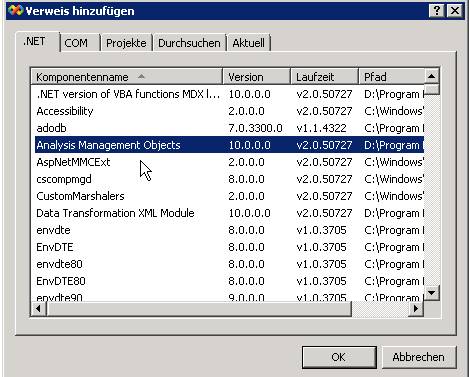
Als erstes muss in C# der Verweis Microsoft.AnalysisServices eingebunden werden. Verwirrenderweise findet man diesen nicht unter Microsoft…, sondern unter Analysis Management Objects (kurz AMO):
Diesen Namespace verwendet man mit
using SSAS = Microsoft.AnalysisServices;
Danach geht es recht einfach:
SSAS.Server server = new SSAS.Server();
try
{
server.Connect(„Data source=<SSAS-Servername>“);
SSAS.Database db = server.Databases.FindByName(„<SSAS-Datenbankname>“);
SAS.Cube cb = db.Cubes.FindByName(„<SSAS-Cubename>“);
}
catch (Exception e) …
Auf die MDX-Skripte hat man dann mit
cb.MdxScripts[0].Commands[0].Text
Zugriff. Diesen String kann man dann auch manipulieren. Damit die Veränderungen auf den Analysis Services gespeichert werden, muss man die Änderungen mit
cb.MdxScripts[0].Update();
speichern.
Ich empfehle die dynamischen MDX-Anteile von den statischen durch Kommentare wie
/*Beginn Statusberechnungen*/n/* Den Text zwischen diesen Markierungen NICHT verändern, da er autogeneriert ist*/n
…
/* Ende Statusberechnungen */
voneinander zu trennen.
Dann kann man auch durch einfache String-Manipulation den zu ändernden Teil herausfischen, ihn ändern und wieder zurückschreiben, ohne den kompletten Cube zu zerstören 🙂
Natürlich muss obiges nicht in einem eigenen C#-Programm programmiert werden, es kann auch als Teil eines SSIS-Pakets verwendet werden.
In einem meiner Projekte verwendete ich einen Data Flow Task, in dem ich die einzelnen Status-Formeln berechnete und in einer Skriptkomponente (als Ziel) die MDX-Skripte in dem Cube aktualisierte. Den Code für die Skriptkomponente habe ich hier als Anlage beigefügt. (Das ist offensichtlich SQL Server 2008, da C# ja erst dann verwendet werden kann 🙂 )
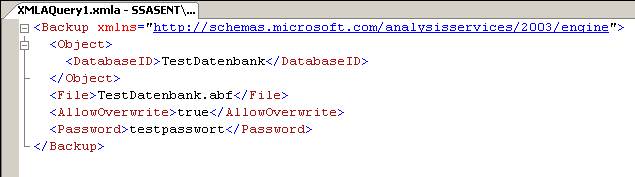
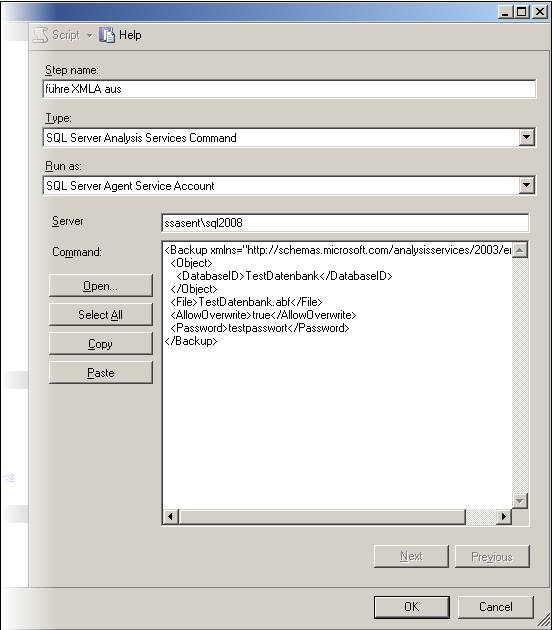
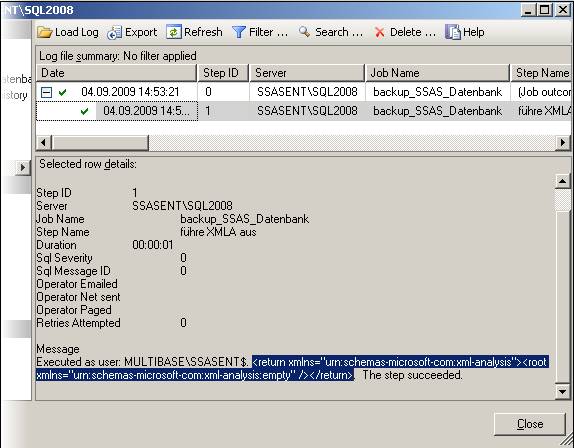
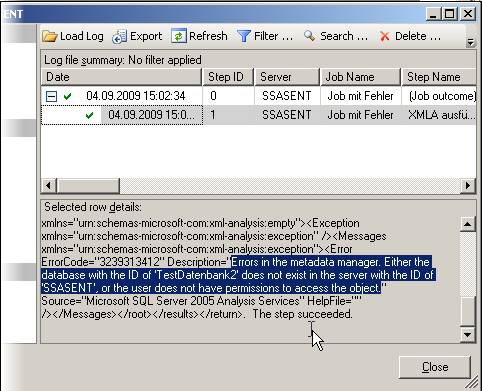
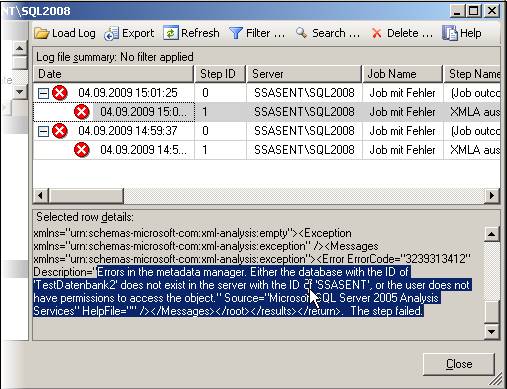
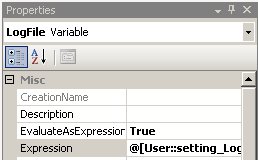
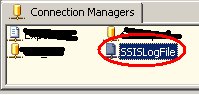
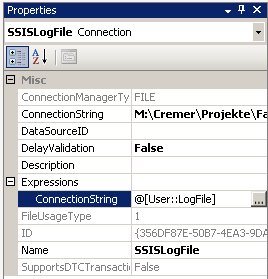
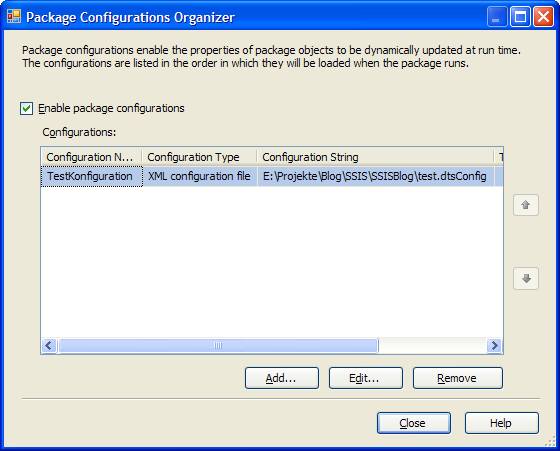
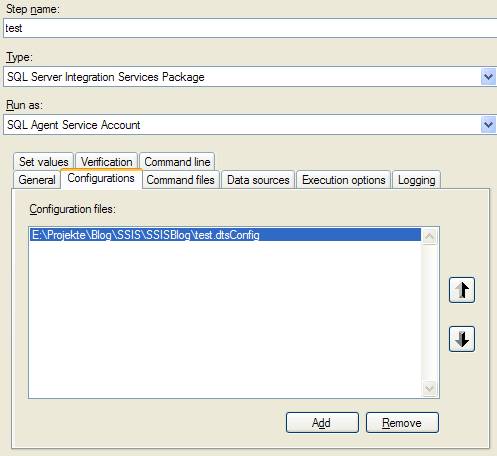
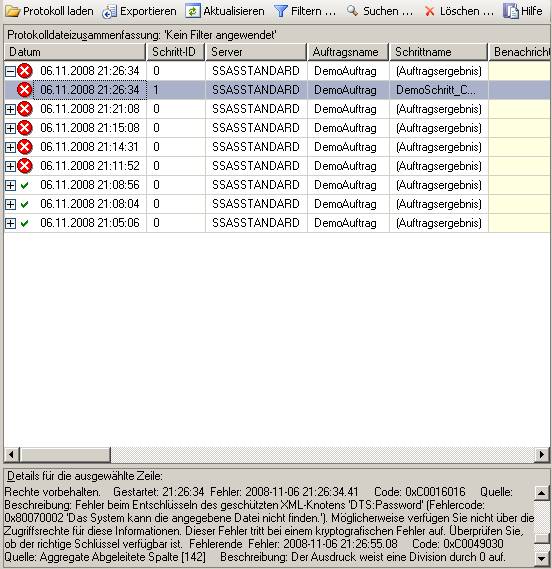
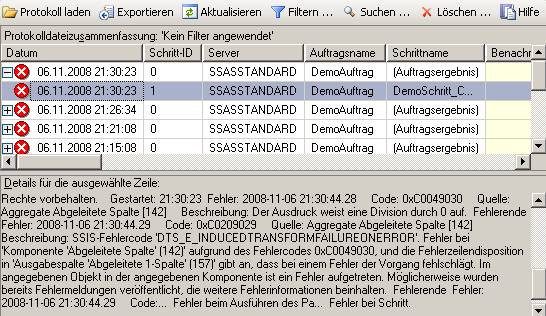
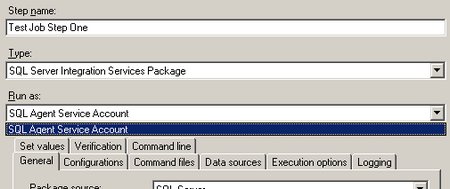
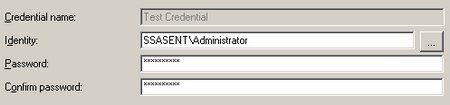
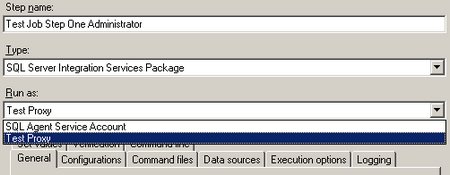
 – muss dieser Credential nun für die Ausführung von SSIS-Paketen definiert werden. Dazu erstellt man einen neuen Proxy unter einem beliebigen Namen, der das neu eingegebene Credential verwendet. Bei den erlaubten Subsystemen setzt man den Haken bei den SSIS-Paketen (und allen weiteren gewünschten Systemen):
– muss dieser Credential nun für die Ausführung von SSIS-Paketen definiert werden. Dazu erstellt man einen neuen Proxy unter einem beliebigen Namen, der das neu eingegebene Credential verwendet. Bei den erlaubten Subsystemen setzt man den Haken bei den SSIS-Paketen (und allen weiteren gewünschten Systemen):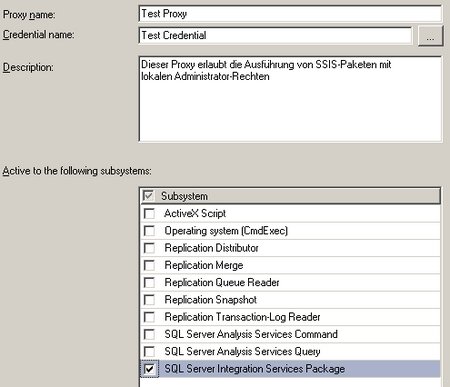
{kind=link}