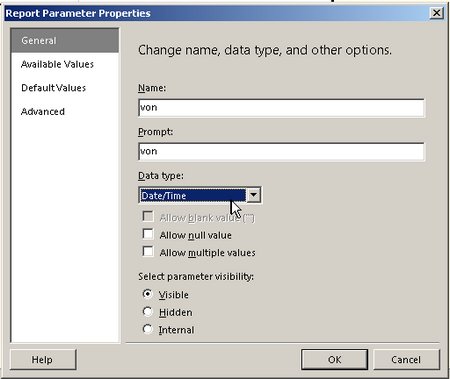
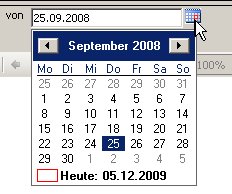
Die Aufgabe in diesem Blog-Eintrag ist es, bei einem gegebenen Dataset nur die ersten 10 Einträge anzuzeigen und den Rest über +/- auf- und zuklappen zu können.
Dazu gibt es einen guten Artikel: http://www.bidn.com/blogs/mikedavis/ssis/172/top-n-bottom-n-grouping-in-ssrs-2008
Allerdings verwendet dieser die Filter-Funktion “Top n” der Gruppe. (Und für den Rest Bottom (Anzahl-n)) Diese hat folgende Nachteile:
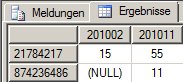
- Wenn der 10. und der 11. Eintrag gleich sind, so zeigen die Top 10 in Wirklichkeit 11 Einträge. Das wäre noch nicht so schlimm, aber:
- Damit sind natürlich auch der 10.-letzte und der 11.-letzte Eintrag gleich, somit kommen beide in dem Rest noch einmal, so dass beide Einträge doppelt erscheinen.
Das sieht dann so aus:

Der Autor hat zwar noch einen weiteren Artikel veröffentlich, in dem er das Problem versucht zu beheben – aber dabei verwendet er SQL-Funktionen. Ich möchte das Problem nur mit SSRS-Features lösen, um eine allgemein gültige Lösung zu haben, zumal in meinem Kundenprojekt MDX zum Einsatz kam.
Mit folgender Anleitung kann man dieses Problem beheben:
Stellen wir uns vor, wir haben ein Dataset wie:

Dieses Dataset zeigen wir in einer Tabelle an – ohne Gruppierung. Das sieht so aus – mit der “Details”-Gruppe:

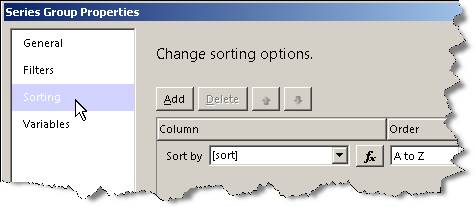
Für die Details-Gruppe setzen wir folgende Eigenschaften:
- Sortierung: Wert absteigend, danach Person aufsteigend. Letzteres ist notwendig, um die Reihenfolge deterministisch zu machen (falls der Wert gleich)
- Sichtbarkeit: über Expression: =RowNumber(Nothing)>5
Damit werden nur die ersten 5 Zeilen angezeigt.
Diese Details sollen die Top 5-Werte anzeigen.
Für die Gruppe, die die restlichen Werte anzeigen soll, legen wir angrenzend daran eine neue Detailgruppe an:

Diese Gruppe stellen wir so ein:
- Details:


- Name: Details_Rest
- Sortierung: Wert absteigend, danach Person aufsteigend.
- Sichtbarkeit: über Expression: =RowNumber(Nothing)<=5
Damit werden die ersten 5 Zeilen nicht angezeigt. - Die Spalten werden wieder mit Person und Wert besetzt.
Nun legen wir jeweils eine übergeordnete Gruppe an:

Die erste Gruppe stellen wir so ein:
- Name: Person_Top
- Gruppieren nach Person, das entspricht also unserer Detailzeile (Allgemein verwenden wir hier den Primärschlüssel)
- Sortierung: wie die Detailgruppe
- Sichtbarkeit: Anzeigen
- Die neu angelegte Spalte Person löschen wir (Wichtig! Nur die Spalte löschen nicht die Gruppe löschen)


Das gleiche machen wir für die zweite Detailzeile und richten auch hier eine übergeordnete Gruppe ein:
- Name: Person_Rest
- Gruppieren nach Person, das entspricht also unserer Detailzeile (Allgemein verwenden wir hier den Primärschlüssel)
- Sortierung: wie die Detailgruppe
- Sichtbarkeit: Anzeigen
Somit sieht unser Bericht so aus:

Ganz links fügen wir eine neue Spalte (außerhalb der Gruppe) hinzu:

Dann löschen wir wieder die unnötige Person-Spalte (ohne die Gruppe zu löschen):

Die Zellen ganz links setzen wir:
- Name = txt_Top
- Inhalt = Top 5
bzw.
- Name = txt_Rest
- Inhalt = Rest
Unser Bericht sieht dann so aus:

Jetzt wollen wir noch das Auf- und Zuklappen implementieren:
- Gruppe Person_Top
- Sichtbarkeit umschalten nach Textbox “txt_Top”
- Gruppe Person_Rest
- Sichtbarkeit: Ausblenden
- Sichtbarkeit umschalten nach Textbox “txt_Rest”


Jetzt muss noch etwas Kosmetik gemacht werden:
- Die txt_Top-Textbox sollte ein – zu Beginn haben und kein +. Also müssen wir bei dieser Textbox den InitialToggleState auf true setzen
- Wenn die Gruppe zusammengeklappt ist, sieht man die erste Person. Deswegen schreiben wir in die jeweiligen Spalten
=iif(count(Fields!Person.Value)>1, Nothing, Fields!Person.Value) bzw.
=iif(count(Fields!Person.Value)>1, Nothing, Fields!Wert.Value)
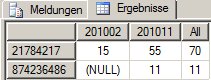
Geschafft!

und

Der Beispielbericht ist hier als Download verfügbar.
Zum Abschluss noch ein paar Worte zur Motivation, warum wir jeweils zwei Gruppen verwenden:
- Die äußere Gruppe wird verwendet, um den “Toggle” zu ermöglichen (also das Ein- und Ausblenden), die inenre Gruppe, um zu definieren, welche Zeilen in der Gruppe sichtbar sind. Da beides über “Sichtbarkeit” geregelt wird, benötigen wir 2 Gruppen.
- Die Alternative wäre, mit Filtern in der Gruppe zu arbeiten. Dann bräuchte man nur eine Gruppe. Leider darf aber RowNumber(…) nicht in Filtern verwendet werden, so dass dieser Weg ausscheidet.
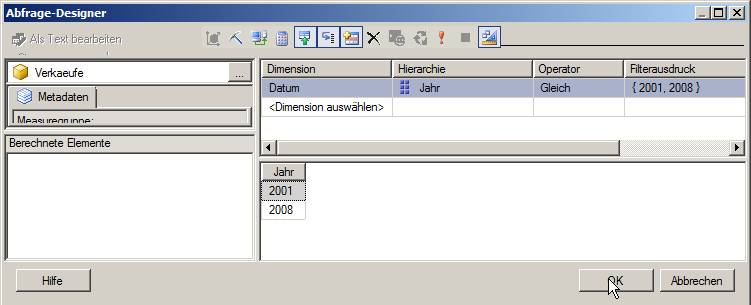
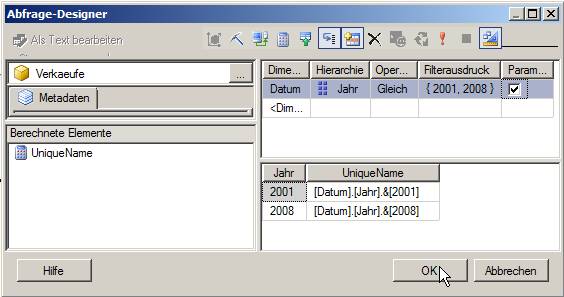

 klicken)
klicken) ):
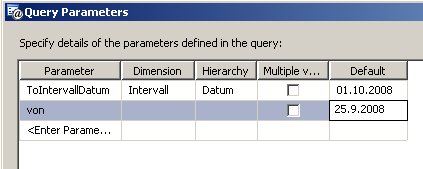
):
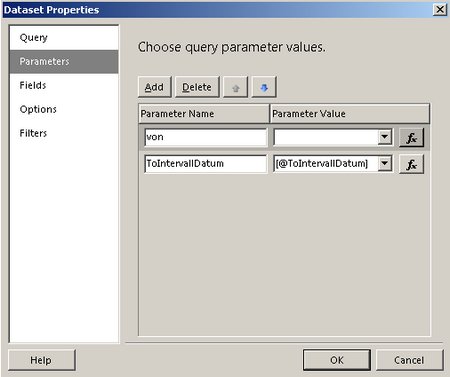
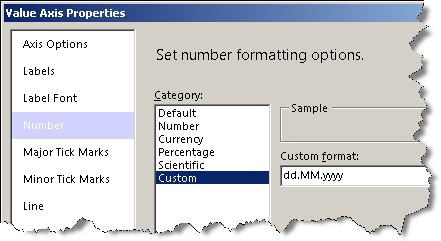
 , den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
, den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime: