Vor kurzem habe ich ja beschrieben, wie man Azure Analysis Services-Cubes von onprem aus verarbeiten kann (s. Beitrag)
Von Azure aus kann man die Verarbeitung sehr schön aus Azure Data Factory v2 starten. Dies ist hier ausführlich beschrieben, auch wenn dieser andere Artikel behauptet, man bräuchte eine Logic App – was aber eben nicht der Fall ist.
Allerdings ist die Beschreibung in dem Artikel nicht mehr ganz aktuell. Der wesentliche Punkt ist, dass man das „ADF service principal“ (in der Form app:applicationid@tenant) als Administrator des Azure Analysis Services-Servers eintragen muss.
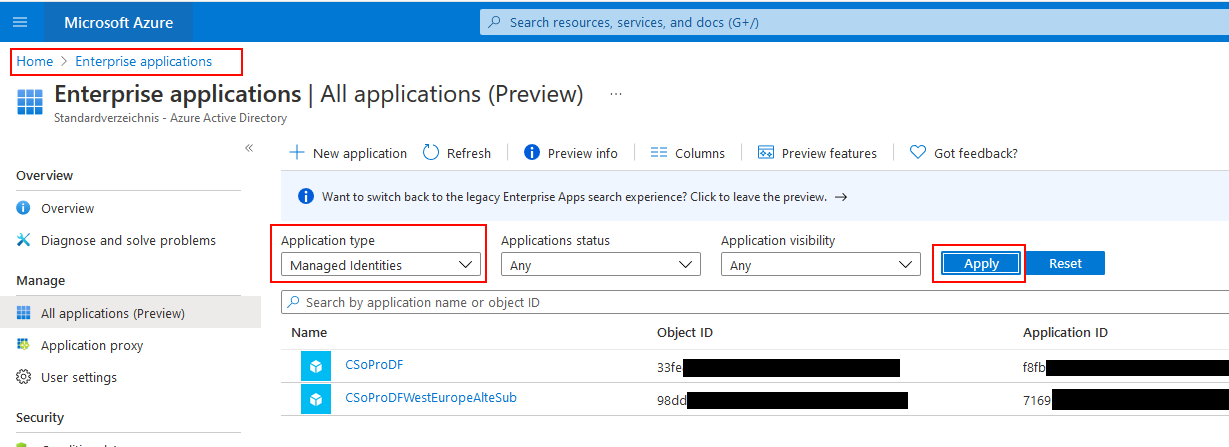
Wo findet man die applicationId?
Man muss im Azure Portal unter Enterprise Applications als Filter „Managed Identities“ einstellen:
Application ID unter Enterprise applications
In der Zeile mit dem Namen der Data Factory findet man rechts die Application ID.
Der Rest aus dem Artikel funktioniert weiter
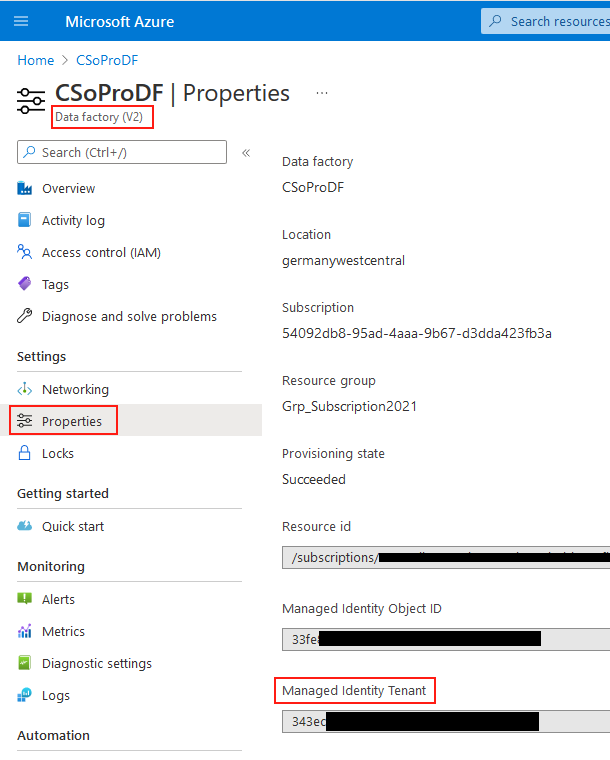
Die tenant ID findet man unter der Azure Data Factory im Reiter Settings:
tenant ID unter den Eigenschaften der Azure Data Factory
Bewertung
Vorteil:
Wenn man die ETLs mit Azure Data factry baut, hat man eine schöne Möglichkeit, in der gleichen Umgebung zu bleiben, wenn man die Cubes verarbeiten muss.
Es ist nett, die Managed Identity zu verwenden. Dann muss man nicht einen speziellen User erstellen, dessen Passwort man dann verwalten müsste.
Nachteil:
Die Berechtigung als Server-Administrator erscheint mir als unschön, da eigentlich die Berechtigung zur Verarbeitung des entsprechenden Cubes ausreichen würde. Leider reicht das hier aber nicht.
Unglücklich finde ich auch bei dem Web-Call, dass das JSON zum Verarbeiten nur ähnlich aber nicht gleich zu dem JSON ist, das zum Beispiel im Management Studio verwendet wird.
Bei einem meiner Kunden hatten wir mehrere Azure Analysis Services im Einsatz. Wenn die kleinsten Tarife nicht mehr ausreichen, kann das mit der Zeit eine teure Angelegenheit werden.
Deshalb haben wir folgende Struktur in den Analysis Services, die in Azure gehostet werden, aufgebaut:
Jedes Projekt hat seinen eigenen Entwicklungsserver
Jedes Projekt hat seinen eigenen Testserver
Es gibt für die Projekte gemeinsame genutzte Produktivserver
Dabei verwenden wir bei den Entwicklungs- und Testservern den niedrigst möglichen Tarif (in der Regel D1, B1).
Darüber sollen die Entwicklungs- und Testserver nur dann laufen und somit Geld kosten, wenn sie benötigt werden. Das heißt, wenn an einem Projekt gerade weder entwickelt noch getestet wird, sind die beiden betreffenden Azure Analysis Services (AAS) pausiert.
Um dies nicht nur manuell durch den Entwickler umzusetzen, haben wir einen Automatismus implementiert:
Zunächst gibt es eine relationale Tabelle, in der alle AAS aufgeführt sind
Für jeden AAS kann man definieren, bis wann er laufen soll (Wenn man z.B. im Test ist, möchte man nicht, dass der Server nachts automatisiert pausiert wird)
Abends läuft ein Job (eine Data Factory Pipeline), die alle auszuschaltenden AAS pausiert, falls sie noch laufen.
Bei der Umsetzung habe ich mich vom hier zu findenden guten Artikel inspierieren lassen.
Erste Pipeline „SuspendOrResumeAAS“
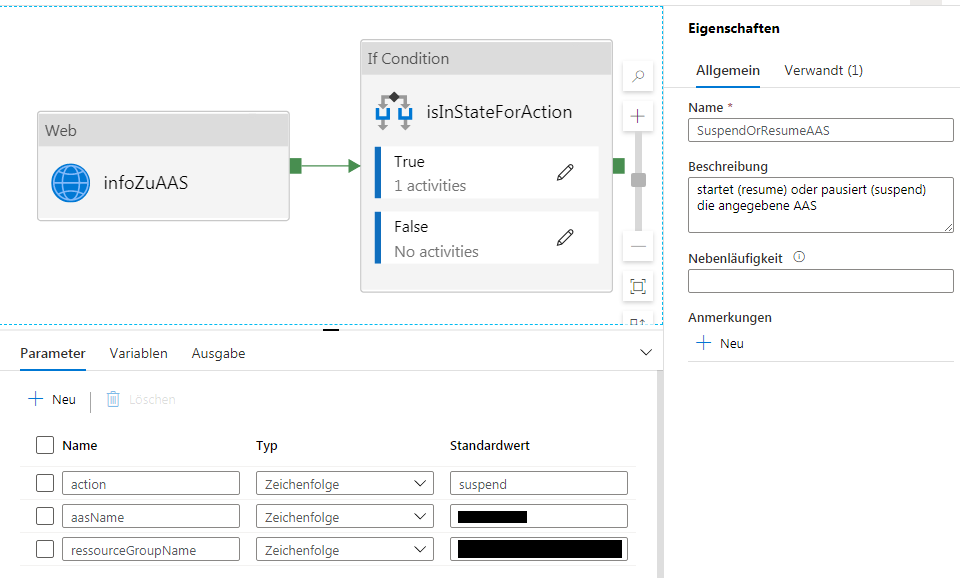
Zunächst erstelle ich eine Pipeline „SuspendOrResumeAAS“:
Pipeline SuspendOrResumeAAS
Man sieht hier schon gut, woraus diese Pipeline besteht:
Es gibt 3 Parameter:
action: Soll die AAS-Instanz pausiert (supend) oder gestartet (resume) werden?
aasName: Name der AAS
ressourceGroupName: Name der Ressourcengruppe
Es gibt eine Variable (was man im Screen Shot nicht sieht):
subscriptionId (Wir werden das später für den API-Aufruf benötigen)
Was macht die Pipeline?
Sie ermittelt zuerst den Status des AAS
Dann wird überprüft, ob der Status zu der Aktion passt (Man kann eine pausierte AAS nicht pausieren 🙂 )
Wenn der Status OK ist, wird der API-Aufruf mit der gewünschten Aktion durchgeführt.
Die Schritte beleuchten wir jetzt näher:
Für die Ermittlung des Status (infoZuAAS) verwenden wir eine Web-Aktivität:
In den Einstellungen bauen wir die URL via dynamischen Inhalt zusammen:
Wie auch im zitierten Artikel vorgeschlagen, verweden wir MSI als Authentifizierung (als Ressource „https://management.azure.com/“ eintragen).
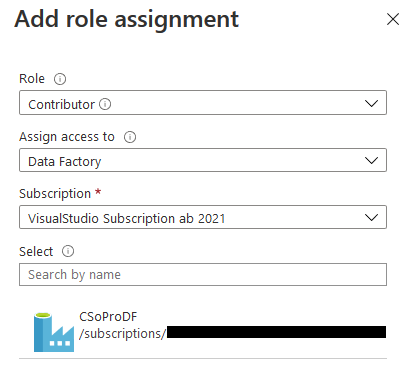
Dazu müssen wir für jede betreffende AAS unter „Access Control (IAM)“ den Punkt „Add role assignments“ auswählen. Dort definieren wir als Contributor die Data Factory, in der wir unsere Pipeline erstellen:
Add role assignment: DF als Contributor des AAS
Wenn wir diese Aktivität im Debug-Modus starten, sehen wir
Debuginformation zu infoZuAAS
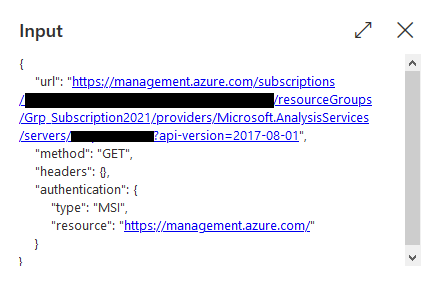
Über die Pfeile (links: Input, rechts: Output) können wir die aufrufende URL kontrollieren:
Input
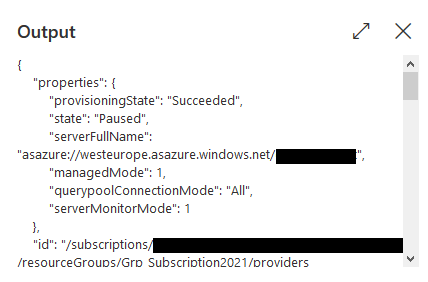
Unter Output sieht man:
Output
Hier sehen wir unter properties > state „Paused“, was heißt, dass die AAS pausiert ist. Für eine laufende AAS ist der state „Succeeded“.
Dies nutzen wir dann gleich in der If-Abfrage (isInStateForAction): Um den Status in der Bedingung abzufragen, kann man via Code darauf zugreifen. Mit activity().output erhält man den gesamten Output und kann dann im JSON über . auf die einzelnen Attribute in der Hierarchie zugreifen:
activity('infoZuAAS').output.properties.state
Der gesamte Code für die „Expression“ in der „If Condition“ sieht so aus:
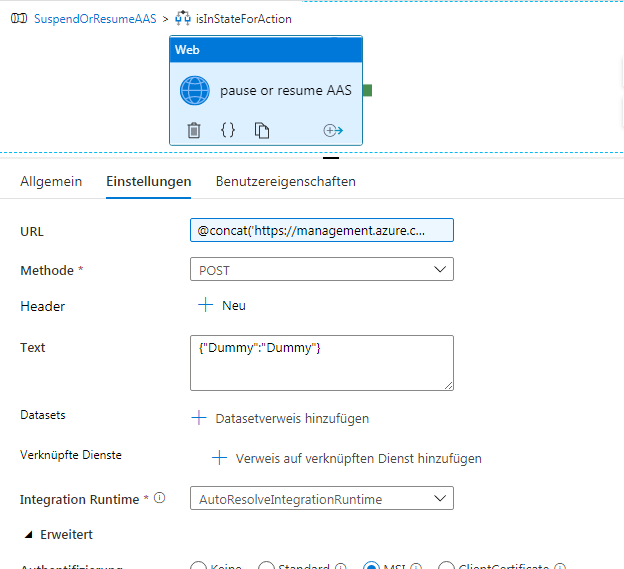
Die innere Aktivität ist wieder eine Web-Aktivität (pause or resume AAS):
Diese Web-Aktivität unterscheidet sich von der vorhergehenden in der URL, in der nun die Aktion (suspend oder resume) mit angegeben wird. Außerdem ist die Methode POST. Deshalb muss der Text mit angegeben werden – auch wenn die AAS-API das eigentlich nicht benötigt, weswegen wir hier {"Dummy":"Dummy"} eintragen.
Authentifizierung und Ressource wird wie oben gesetzt.
Zweite Pipeline: alleAASausschalten
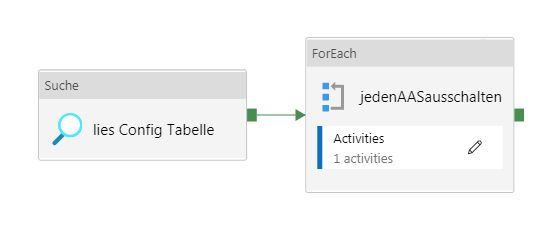
Pipeline alleAASausschalten
Die Suche/Lookup-Aktivität „lies Config Tabelle“ liest per Query aus einer SQL-Server-Tabelle, welche AAS auszuschalten sind:
SELECT AAS_Name, RessourceGroupName FROM Management.[Config_AAS_Shutdown]
WHERE getdate() > keep_Online_Until
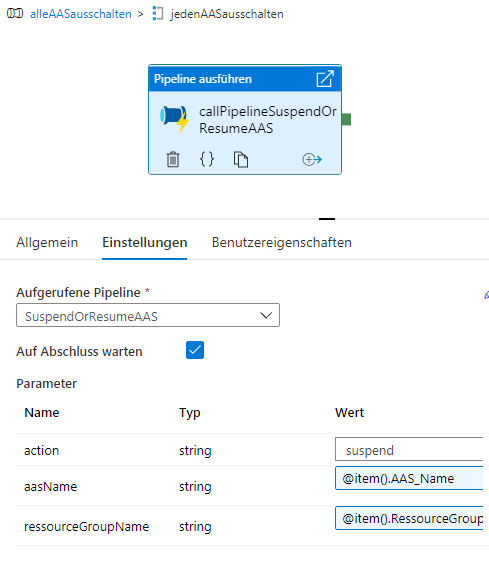
In der For-Each-Schleife „jedenAASausschalten“ ist folgende Einstellung zu machen:
@activity('lies Config Tabelle').output.value
Und innerhalb der Schleife wird eine Aktivität ausgeführt:
die unter (1) erstellte Pipeline aufrufen
Als Parameter übergeben wir an diese Pipeline:
action: suspend (fest definiert)
aasName: Formel @item().AAS_Name
ressourceGroupName @item().RessourceGroupName
Somit müssen wir nur noch einen Trigger täglich um 19 Uhr definieren.
Weitere Möglichkeiten
Wir haben darauf verzichtet, einen Automatismus zu erstellen, der am Vormittag die Entwickler-Server wieder hochfährt.
Hintergrund war, dass wir die Entwicklungs- und Testserver nicht jeden Tag brauchen. Sie schnell manuell zu starten, ist kein großer Aufwand – deswegen lassen wir das so.
Aber natürlich wäre es einfach, ganz analog eine Pipeline zu erstellen.
Uns war aber wichtig, den hier vorgestellten Weg zu implementieren, da man als Entwickler schnell mal vergisst, einen AAS auszuschalten – und mit diesem Automatismus ist das kein Problem, da jede Nacht überprüft wird, ob die AAS aus sind – und, wenn nicht, wieder ausgeschaltet werden.
Meine Erfahrungen in der Business Intelligence Welt