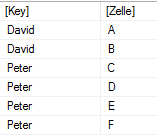
Das ist also die Lösung des Problems. Natürlich kann man noch die Value-Spalte löschen, z.B. mit SELECTCOLUMNS.
Wir haben uns hier folgendes zu nutze gemacht:
Wenn man als Trenner | verwendet, kann man die eingebauten Funktionen PATHITEM, PATHLENGTH verwenden
Wenn man einen anderen Trenner verwendet, kann man ggf. den Trenner durch | ersetzen
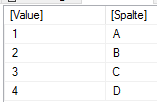
GENERATESERIES erzeugt eine einspaltige Tabelle (Spalte heißt Value) mit Zahlen von 1 bis n
Für Fortgeschrittene: Einen String in einer Tabelle splitten
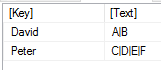
Im obigen Beispiel haben wir einen Text gesplittet. Nun kann es aber sein, dass man in einer Tabelle eine Spalte hat, die man splitten will und dann entsprechend mehr Zeilen bekommen will.
Zunächst erstelle ich die Ausgangstabelle wie oben. Dies steht dann in der Variable tabelle:
Ausgangstabelle
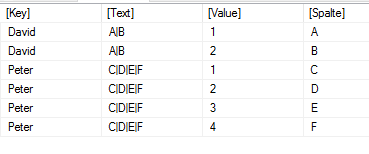
Das GENERATE führt dann für jede Zeile die GENERATESERIES – Funktion aus. Dort steht der jeweilige Text aus der Zeile. Die PATHLENGTH ist also für die erste Zeile 2, für die zweite 4. Das Ergebnis vom GENERATE ist somit:
Über das Addcolumns holen wir uns die jeweilige Stelle aus dem zu splittenden String:
Wir hatten einen Cube (tabular model), das wir ausreichend getestet hatten. Wir hatten auch Filter (Slices in Power BI bzw. Filter in Excel Pivot) auf das Attribut Land getestet.
Als wir aber nun eine Rolle anlegten, die auf ein Land filterte, funktionierten unsere Berichte nicht mehr für diese Personen.
Da mich das sehr überrascht hat, möchte ich hier die Details beschreiben.
Beispiel-Cube
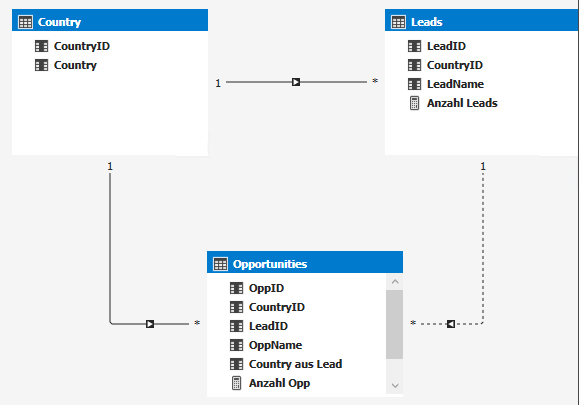
Wir erstellen einen Cube mit 3 Tabellen:
Country
Lead
Opportunity
Leads und Opportunities haben jeweils ein Land – und sind damit mit der Tabelle Country verbunden.
Opportunities können aus Leads hervorgehen. Dafür haben Opportunities eine LeadID, die aber leer sein kann. Außerdem kann das Land des Leads unterschiedlich vom Land der daraus generierten Opportunity sein.
Da diese Relationen einen Zirkel bedeuten würden, ist die Beziehung zwischen Lead und Opportunity auf inaktiv gesetzt – und kann dann über USERELATIONSHIP() in einem Measure verwendet werden.
Datenmodell mit aktiven und inaktiven Verbindungen
Als Measures definieren wir:
Anzahl Leads:=COUNTROWS(Leads)
Anzahl Opp:=COUNTROWS(Opportunities)
Anzahl Opportunities via Leads:=CALCULATE(COUNTROWS(Opportunities), USERELATIONSHIP(Leads[LeadID],Opportunities[LeadID]))
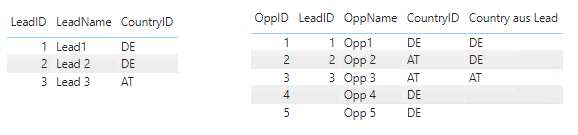
In den Tabellen haben wir folgende Beispieldaten:
Beispieldaten
Somit ergeben sich für die Measures folgende Ergebnisse:
Filter
Measure
Wert
IDs
ohne
Anzahl Leads
3
1,2,3
ohne
Anzahl Opp
5
1,2,3,4,5
ohne
Anz Opp via Lead
5
1,2,3,4,5
Deutschland
Anzahl Leads
2
1,2
Deutschland
Anzahl Opp
3
1,4,5
Deutschland
Anz Opp via Lead
2
1,2
Österreich
Anzahl Leads
1
3
Österreich
Anzahl Opp
2
2,3
Österreich
Anz Opp via Lead
1
3
Ergebnisse
Soweit ist das wenig überraschend.
Wenn wir jetzt aber eine Rolle mit Row Level Security – Filter =Country[Country]="Deutschland" definieren, so hätte ich erwartet, dass wir die Werte erhalten, die in obiger Tabelle unter Deutschland stehen.
Das stimmt auch für die beiden ersten Measures. Allerdings gibt das Measure „Anzahl Opportunities via Leads“ folgenden Fehler zurück:
Error: The UseRelationship() and CrossFilter() functions may not be used when querying ‚Opportunities‘ because it is constrained by row-level security defined on ‚Leads‘ or related tables.
Das finde ich sehr verblüffend. Eigentlich halte ich das für einen Bug. Da er aber so (mindestens) seit SSAS 2016 enthalten ist, gehe ich davon aus, dass Microsoft das nicht so sieht.
Deswegen sollte man mit USERELATIONSHIP() sehr sparsam umgehen, da sich dadurch Nebeneffekte auf Row Level Security ergeben.
(Nur als Randbemerkung: Bei meinem Kunden hatte ich eine andere Fehlermeldung (ambiguous paths). Ich weiß nicht, ob es am Patch-Level lag oder ich die Situation nicht 100% genau nachstellen konnte)
In der Regel lesen Cubes (tabulare Modelle) Daten aus einem DWH, also meist relationalen Datenbanken. Es kann aber sinnvoll sein, das Ergebnis eines Cubes als Quelle für einen anderen Cube zu verwenden. In einem Kundenprojekt benötigten wir das, weil die Preisberechnung in einem Cube implementiert war und in einem anderen Cube verwendet werden sollte.
Dann hat man also ein oder mehrere DAX-Statements, die man in den Cube laden will. Während die Verwendung eines DAX-Statements gradlinig funktioniert, ist es schwer, mehrere DAX-Statements (mit dem gleichen Cube als Quelle) zu verwenden.
Dieser Post zeigt, wie es funktioniert.
Problem
Nehmen wir für unser Beispiel an, dass wir zwei DAX-Abfragen von einem bestehenden Cube in einen neuen Cube importieren wollen. Um ein einfaches Beispiel zu haben, verwenden wir als Abfrage einfach:
evaluate {1}
Dies liefert eine Tabelle mit einer Spalte („[Value]“) und einer Zeile, die den Wert 1 hat.
Um diese Abfrage in den neuen Cube zu laden, gehen wir ganz normal im Visual Studio vor – genauso wie man es in Power BI auch machen würde:
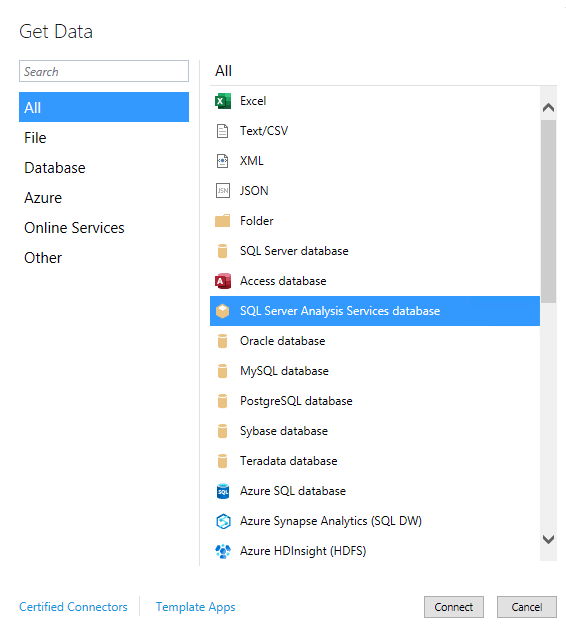
Wir definieren eine neue Datenquelle vom Typ „SQL Server Analysis Services-Datenbank“:
Eingabe eins DAX-Statements bei einer neu erstellten Datenquelle vom Typ SSAS
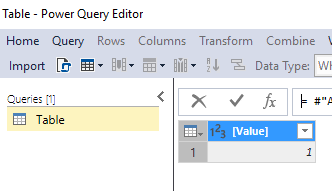
Um diese Daten als Tabelle im Cube zu haben, muss man auf der Datenquelle rechte Maustaste > „Import New Tables“anklicken. Das Power-Query-Fenster öffnet sich:
Power-Query-Editor für die DAX-Abfrage
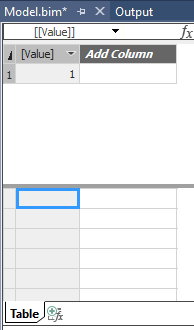
Über „Import“ wird diese Abfrage automatisch ausgeführt und man erhält eine neue Tabelle mit Namen „Table“, die nur eine Spalte „[Value]“ hat und dort eine Zeile mit 1:
Tabelle mit Ergebnis des DAX-Statements
Versucht man aber nun analog eine zweite Abfrage (mit evaluate {2}) auszuführen, scheint es zunächst zu funktionieren. Allerdings wird keine zweite Datenquelle angelegt, sondern die bestehende verändert, so dass bei einem Refresh die oben gezeigte Tabelle eine 2 statt einer 1 zeigt.
Es ist nicht möglich, zwei unterschiedliche DAX-Abfragen auf dieselbe Quelle abzufeuern
Man muss es also anders probieren.
Lösungsidee
Bei meinem Blogeintrag zur Datumsdimension in SSAS hatte ich bereits die M-Syntax Value.NativeQuery verwendet. Dies werden wir hier mit der Datenquelle SSAS verwenden.
Dazu gehen wir wie folgt vor:
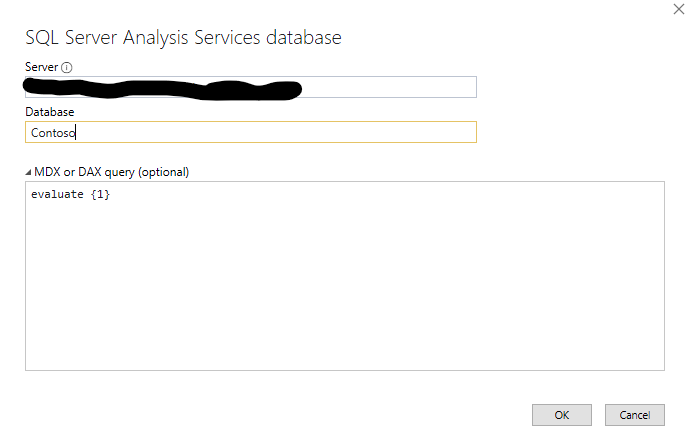
Zunächst löschen wir die Datenquelle mit dem DAX-Statement und erstellen eine neue, allerdings ohne Eingabe eines DAX-Statements.
Quelle vom Typ SSAS
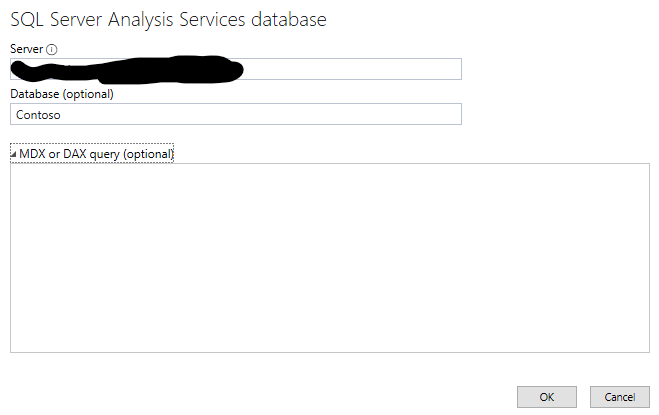
Im zweiten Fenster geben wir nur die Connection an:
Verbindung zu einer SSAS Datenbank – ohne DAX-Statement
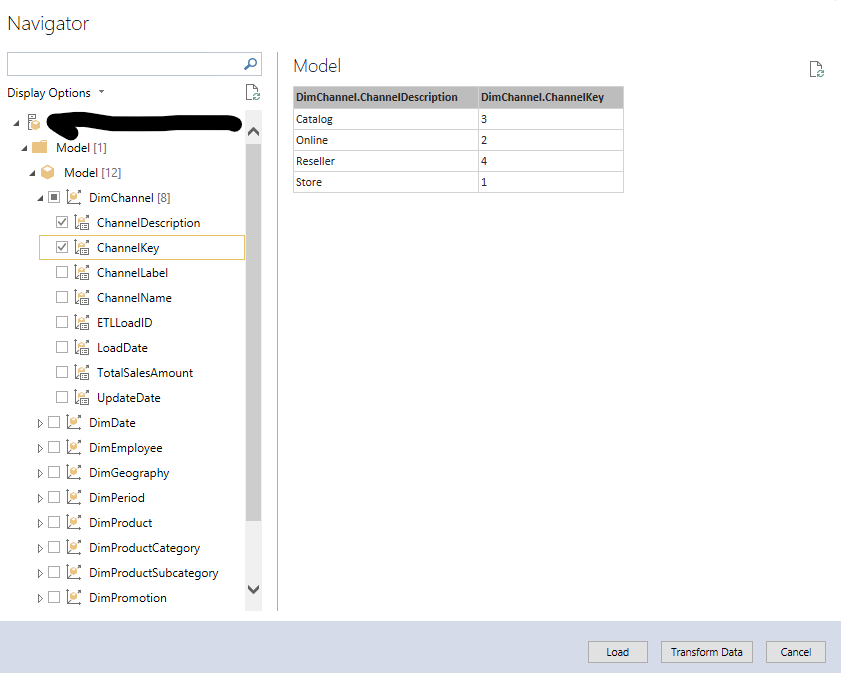
Um auszuprobieren, ob sie funktioniert, gehen wir mit der rechten Maustaste auf diese Verbindung und klicken auf „Import new tables“:
Auswahl einer kleinen (!) Tabelle
Wir sollten darauf achten, dass wir eine kleine Tabelle auswählen. Dann klicken wir auf „Load“.
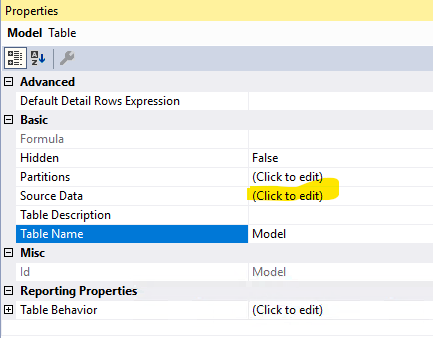
Damit wird eine neue Tabelle namens „Model“ mit dieser Struktur angelegt. Das M hinter der Abfrage finden wir in den Eigenschaften bei Source Data:
Eigenschaften der neuen Tabelle –> Source Data, um M zu sehen
Das M-Statement sieht so aus:
let
Source = #"Name der Datenquelle",
Model1 = Source{[Id="Model"]}[Data],
Model2 = Model1{[Id="Model"]}[Data],
#"Added Items" = Cube.Transform(Model2,
{
{Cube.AddAndExpandDimensionColumn, "[DimChannel]", {"[DimChannel].[ChannelDescription].[ChannelDescription]", "[DimChannel].[ChannelKey].[ChannelKey]"}, {"DimChannel.ChannelDescription", "DimChannel.ChannelKey"}}
})
in
#"Added Items"
Wenn wir das Statement nun so abändern, haben wir die Problemstellung gelöst:
let
Source = #"Name der Datenquelle",
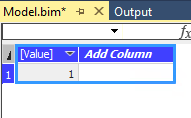
Tabelle = Value.NativeQuery(Source, "evaluate {1}")
in
Tabelle
Nach dem Löschen der alten zwei Spalten und einem Refresh, sieht das Ergebnis wie gewünscht aus:
Ergebnis der DAX-Abfrage als Tabelle
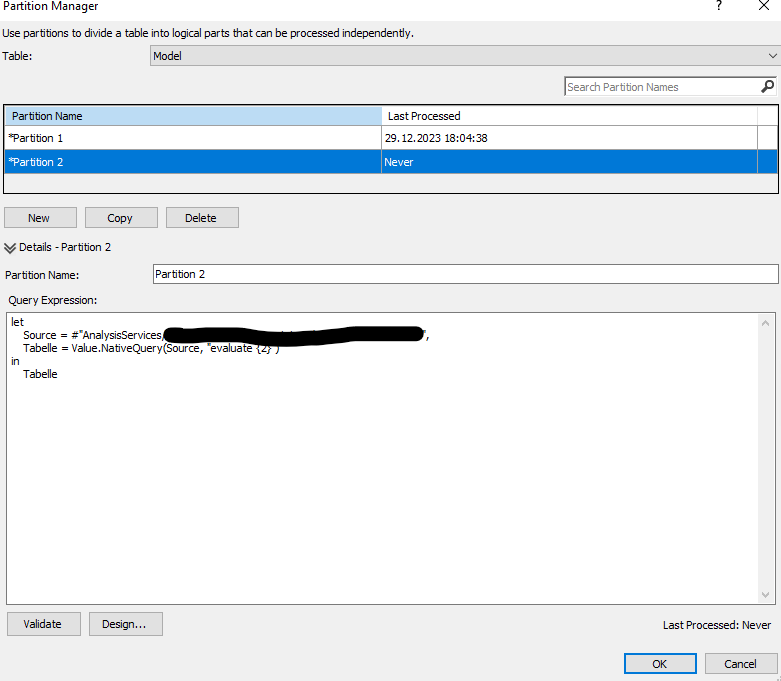
Um nun zu zeigen, dass die zweite Abfrage auch funktioniert, erstellen wir einfach eine zweite Partition mit der gleichen M-Abfrage, wobei wir nur 1 durch 2 ersetzen:
2 Partitionen
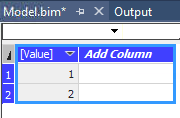
Nach einem Refresh auf die Tabelle haben wir das Ergebnis:
fertig: Beide DAX-Statements wurden ausgeführt
Damit sind wir fertig!
Ich habe absichtlich das Beispiel der Partitionen verwendet, da dies ein klassisches Anwendungsszenario ist, bei dem mehrere Abfragen auf die gleiche Quelle abgefeuert werden müssen.
Optimierungen
Der Nachteil an dieser Implementierung ist, dass das DAX-Statement immer komplett geschrieben werden muss.
Wenn man sich aber nun vorstellt, dass es ein kompliziertes DAX-Statement ist, das sich je Partition nur um eine Zahl unterscheidet (in unserem Beispiel eine Zahl von 0 bis 99), dann möchte man das DAX-Statement nicht 100x schreiben – weil das natürlich sehr schlecht zu warten ist.
Deswegen sehen bei uns die M-Befehle so aus:
let
Source = #"Name der Datenquelle",
P = Value.NativeQuery(
Source, Text.Combine({Vorne, "1", Hinten}, "")
)
in
P
Wir sehen, dass wir zwei Variablen (Vorne und Hinten) verwenden. In der gezeigten Partition wird dann die Zahl 1 zwischen Vorne und Hinten eingetragen.
In unserem Beispiel aus dem Blog wäre
Vorne = "evaluate {"
und
Hinten = "}"
Jetzt ist nur noch die Frage, wo wir diese Variablen hinterlegen können. Das sind die Expressions:
Expressions
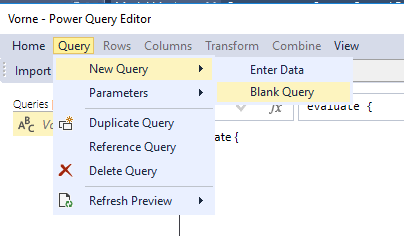
Um diese zu erstellen, klicken wir mit der rechten Maustaste auf „Expressions“ und dann auf „Edit Expressions“:
Dann legen wir eine leere Query an:
eine leere Quelle im Power Query Editor anlegen
Die Query können wir umbenennen über die Name-Property. Den Wert der Variablen tippen wir oben einfach ein:
Beispiel der Variable „Vorne“
In unserem echten Anwendungsfall haben wir den Text (hier evaluate { ) nicht einfach eingetragen, sondern mit = zugewiesen, also = "evaluate {" geschrieben. Dann muss man Anführungszeichen, die in dem DAX-Statement vorkommen, verdoppeln, da der Interpreter sonst denkt, der String wäre zu Ende.
In (tabular) Cubes möchte man möglicherweise Berechnungen durchführen, bei denen die Anzahl der Tage zwischen zwei Datumswerten ermittelt werden sollen.
Überraschender Weise gibt es keine DateDiff-Funktion in DAX.
Zwar kursieren im Web einige Beispiele für einen Ersatz, allerdings gefallen sie mir nicht.
Hintergrundwissen
Deswegen schauen wir uns zunächst näher an, wie in (tabular) Cubes Datumswerte gespeichert werden:
Datumswerte werden intern als Zahlen gespeichert, wobei der ganzzahlige Anteil die Anzahl der Tage seit 30.12.1899 angibt und der Nachkommaanteil die Uhrzeit.
Wir können das ganz leicht im Cube sehen, indem wir ein Datum mit 1.0 (deutsch 1,0) multiplizieren (im DAX reicht *1. bzw. *1, – je nachdem welche Lokalisierung eingestellt ist ) – oder über value(…) in eine Zahl konvertieren.
Ich habe einen kleinen Cube erstellt – mit folgender Datenquelle:
select convert(datetime, ‚17.8.2011 17:53:12‘, 104) as DatumUhrzeit, convert(date, ‚17.8.2011‘, 104) as Datum UNION ALL select convert(datetime, ‚1.3.2000 06:13:27‘, 104), convert(date, ‚1.3.2000‘, 104) UNION ALL select convert(datetime, ‚5.3.2000 01:13:27‘, 104), convert(date, ‚5.3.2000‘, 104) UNION ALL select convert(datetime, ‚1.1.1900 5:30:00‘, 104), convert(date, ‚1.1.1900‘, 104) UNION ALL select convert(datetime, ‚31.12.1899 17:30:00‘, 104), convert(date, ‚31.12.1899‘, 104) UNION ALL select convert(datetime, ‚27.12.2014 20:22:55‘, 104), convert(date, ‚27.12.2014‘, 104) UNION ALL select getdate(), convert(date, getdate())
Dann habe ich jeweils eine berechnete Spalte – wie oben beschrieben – hinzugefügt. Das Ergebnis:
DateDiff von Dates
Um nun die Differenz zwischen 2 Date-Spalten zu ermitteln, muss man sie nur voneinander abziehen. Das Ergebnis hat allerdings den Datentyp DateTime, weswegen man das Ergebnis noch in ein int verwandeln muss:
([Datum2] –[Datum1]) * 1
oder
int([Datum2]-[Datum1])
Um das zu demonstrieren, habe ich meine Quelle angepasst und das Ergebnis sieht so aus:
DateDiff von DateTimes
Wenn wir aber 2 DateTimes haben, dürfen wir sie nicht einfach voneinander abziehen (also int([DatumUhrzeit2]-[DatumUhrzeit1])), da die Uhrzeiten keine rolle spielen sollen. Stattdessen müssen wir die Datumswerte zunächst nach int konvertieren (dabei rundet DAX immer ab) und dann subtrahieren:
int([DatumUhrzeit2])-int([DatumUhrzeit1])
Wir sehen, dass die falsche Methode immer dann einen zu niedrigen Wert ausweist, wenn das abgezogene Datum eine größere Uhrzeit als der Minuend aufweist.
Erweiterungen: Alter
Falls mein ein Alter bis heute berechnen will, kann man das mit der gleichen Logik machen. Die DAX-Funktionen sind:
now() liefert das heutige Datum inkl. aktueller Uhrzeit
today() liefert nur das heutige Datum
Diese Funktionen werden im übrigen beim Process aufgerufen und nicht beim Auswerten in einem Frontend-Programm
Erweiterungen: DateDiff in Sekunden
Ganz analog kann man natürlich vorgehen, um die Differenz in anderen Einheiten auszurechen:
Man multipliziert einfach die DateTime-Spalte mit dem entsprechenden Wert:
* 24 für Stunden
* 24 * 60 für Minuten
* 24 * 60 * 60 für Sekunden
und konvertiert dann die Zahl in ein int.
Allerdings kann so eine Differenz in Monaten bzw. Jahren nicht berechnet werden. Das müsste man zunächst wohl definieren (Was bedeutet 17.1.2015 18:33 – 18.3.2012 17:55 in Monaten?) und dann ggf. über if-Statements selbst berechnen.
Meine Erfahrungen in der Business Intelligence Welt